Architectures for Central Server Collaboration
Matthew Weidner |
Jun 4th, 2024
Home | RSS Feed
Keywords: rebasing, CRDTs, Operational Transformation
This blog post records some thoughts on how to architect a real-time collaborative app when you do have a central server.
It is on the speculative side, since my own experience centers on server-optional collaborative apps using CRDTs. Nonetheless, I hope that this post can provide a useful overview of different architectures, while also giving perspective on where classic CRDT/OT approaches are useful and where they might be overkill.
The architectural techniques below come from a variety of collaborative apps and devtools, summarized in the Classification Table at the end. Additionally, the following sources serve as theoretical inspiration:
- A Framework for Convergence, Matt Wonlaw (2023).
- Collaborative Editing in ProseMirror, Marijn Haverbeke (2015).
- Operational Version Control, Jonathan Edwards (2024).
Modeling Central Server Apps
Here is a simple abstract model that describes many apps with a central server and multiple users:
- The server stores some state that changes over time. (User status, task list, multiplayer game world, etc.).
- User interact with the state by submitting operations to the server. (“set status”, “mark task as completed”, “pick up loot”, etc.) Each time the server receives an operation, it uses app-specific business logic to validate the operation and possibly update the state.
- Occasionally, the server sends the latest state to users, so that they can update their local views.
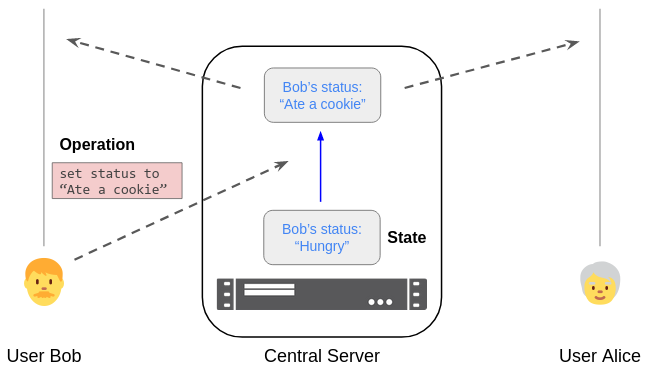
Bob submits a "set status" operation to the server using a form. The server processes it, updates its state, and sends the new state to Bob and Alice.
Notation: time proceeds upwards; diagonal arrows indicate network messages.
In early web apps, updating the user’s local view of the state required refreshing the page. This was true even for the user’s own operations: to perform an operation, the user’s browser would submit a form and display the returned HTML. Later, AJAX let users submit operations and receive updates without reloading the whole page, but they often still needed to wait for a response from the server before seeing the effects of their own operations.
Real-time collaborative apps like Google Docs, Figma, and many multiplayer games instead let users see their own operations immediately, without waiting for a response from the server. These instant local updates are merely optimistic—the operation might be rejected by the server, or modified by concurrent user actions—but they nevertheless improve the user experience, by reducing user-perceived latency. Real-time collaborative apps can even choose to allow offline work, by storing operations for later submission while still updating the local state immediately.
Server-Side Rebasing
Even before adding real-time collaboration, our simple abstract model hides an important challenge: What should the server do in situations like Figure 1, where Bob submits an operation that arrives after a concurrent operation from Alice?
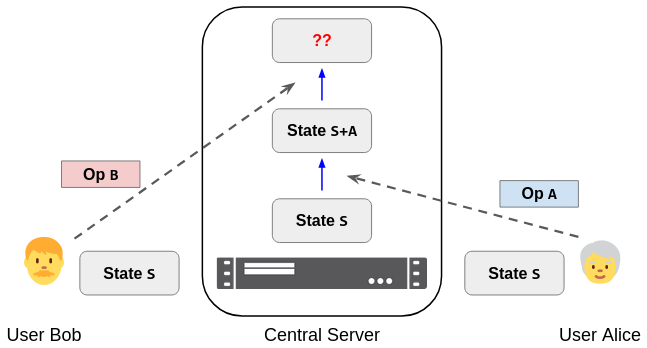
Figure 1. Starting in state S, Bob submits operation B to the server. But before it arrives, the server processes Alice's concurrent operation A, changing the state to S + A.
The issue here is that Bob expected his operation B to apply to some state S, but it was instead applied to the state S + A. I call this server-side rebasing, by analogy with git rebasing. Depending on the details of the specific situation, the original operation B might no longer make sense in state S + A:
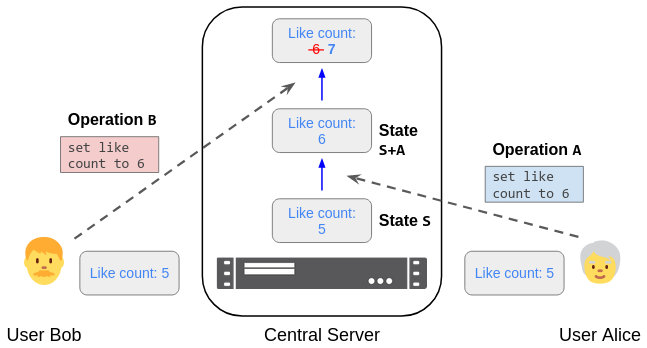
- Suppose Alice and Bob both “like” a social media post. If the post started with 5 likes, Alice and Bob could each send the operation “set like count to 6”. But when Bob’s operation arrives, the count is already 6; his rebased operation should instead increase it to 7.
- In a multiplayer game, suppose there is some loot on the ground and Alice and Bob each try to pick it up. If you phrase their operations as “add loot to my inventory; delete loot from ground”, then they will both end up with the loot in their inventory, duplicating it.
- In a word document, if Bob’s edit is phrased as “set document state to
"xyz..."”, then his change will overwrite Alice’s concurrent edits. This might be okay for individual paragraphs (e.g., Notion blocks), but for a large document with Alice and Bob editing different places simultaneously, Alice would prefer that Bob’s rebased operation preserves her concurrent edits (like Google Docs).
Here are three common solutions to the server-side rebasing challenge.
1. Serialization
In situations like Figure 1, the server rejects Bob’s operation. His client must download the new state S + A and then retry with an updated operation B'.
Examples:
- In the like-count example above, Bob’s client could read the new like count (6) and retry with an updated operation “set like count to 7”.
- The ProseMirror rich-text editor’s built-in collaborative editing system rejects operations like
B. Upon learning of this rejection, Bob’s client will compute a rebased operationB'that “does the same thing” to the new document state, using ProseMirror’s built-in rebasing function, then submitB'to the server. - In git, if you
git pushto a remote branch that has more commits (= operations) than your local branch, the remote branch will reject your push. You can then usegit pull --rebase && git pushto download the new state, rebase your local commits, and retry. Note that unlike in most real-time collaborative apps, this might require human input.
I call this approach “Serialization” by analogy with SQL’s serializable isolation level.
Note that serialization does not actually solve the rebasing problem; it just defers it to clients, who must rebase the operations themselves. Also, in apps with many active users, frequent rejections can lead to performance issues and even lock out users—see StepWise’s ProseMirror blog post.
2. CRDT-ish
Operations are designed to “make sense” as-is, even when applied to a slightly newer state. That is, in situations like Figure 1, the server applies operation B directly to the state S + A and hopes that the result looks reasonable to users.
Examples:
- In the like-count example above, Alice and Bob can rephrase their operations as “add 1 to the like count” (or “add my user ID to the has-liked set”).
- In the multiplayer game example above, the server can treat a “pick up loot” action as “if the loot is on the ground, add it to the player’s inventory, else do nothing”. That way, if Bob tries to pick up a loot item but Alice picks it up first, Bob’s operation is ignored—the item is not added to his inventory. The server can likewise ignore any subsequent attempts by Bob to use that item, since it isn’t in his inventory.
- In a todo-list app, if operation
Amarks a task as completed while operationBchanges the task’s content, the server can choose to process both operations as-is. This is simple to implement if you treat the two operations as acting on independent states—the “done” checkmark and the text content—instead of overwriting a whole object{ done: boolean; content: string }. On the other hand, maybe your business logic doesn’t allow edits to completed tasks, in which case the server can do something else.
I call this approach “CRDT-ish” because CRDTs also use operations that can be applied as-is to newer states. Thus studying CRDT techniques can help you design operations that “make sense” like in the examples above.
Note that you don’t need to use literal CRDTs, which are often overkill in a central server app. In particular, your operations don’t need to satisfy CRDTs’ strict algebraic requirements (commutativity / lattice axioms). Whether operations “make sense” in new states is instead a fuzzy, app-specific question: it depends on your app’s business logic and what users expect to happen, and it’s okay to be imperfect.
I personally find designing CRDT-ish operations a lot of fun, though it can require a special way of thinking. From the server’s perspective, it just needs to apply operations to its state in serial order, which is dead simple.
Performance-wise, literal CRDTs were historically criticized for storing lots of metadata. This is less of a problem with modern implementations, and the central server can help if needed.
3. OT-ish
In situations like Figure 1, the server transforms B against A, computing a new operation B' that is actually applied to the state. More generally, the server applies a transformation function T to each intervening concurrent operation in order:
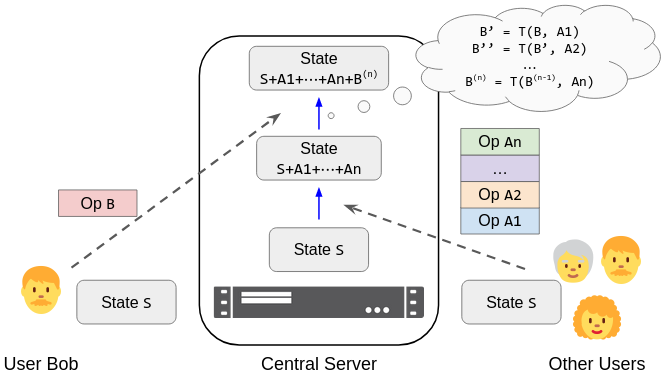
Examples:
- In the like-count example above, a reasonable transformation function is
T(set(n), set(_)) = set(n+1). That way, Bob’s operationset(6)transforms against Alice’s intervening concurrent operation to yieldset(7). - In the multiplayer game example above, a reasonable transformation function is:
T(pickUp(userB, Y), pickUp(userA, X)) = if X = Y return noop() else return pickUp(userB, Y)That way, if Alice and Bob both try to pick up the same item, the second operation (Bob’s) is transformed into a no-op.
I call this approach “OT-ish” because Operational Transformation (OT) systems also transform each operation against intervening concurrent operations. As in the previous section, literal OT algorithms are probably overkill. In particular, your transformation function doesn’t need to satisfy OT’s strict algebraic requirements (the Transformation Properties).
OT-ish systems are well established in practice. In particular, Google Docs is a literal OT system. However, most published info about OT focuses on text editing, which is difficult but only a small part of many apps.
Performance-wise, OT-ish systems can struggle in the face of many simultaneous active users: the server ends up doing O(# active users) transformations per operation, hence O((# active users)^2) transformations per second. Also, the server needs to store a log of past operations for transformations, not just the current state. You can garbage collect this log, but then you lose the ability to process delayed operations (e.g., users’ offline edits).
Challenge: Text and Lists
There is one case where server-side rebasing is especially tricky, no matter which of the three above solutions you use: editing text and lists. (Extensions to text, like rich text and wiki pages, are likewise hard.)
Figure 2 illustrates the challenge:
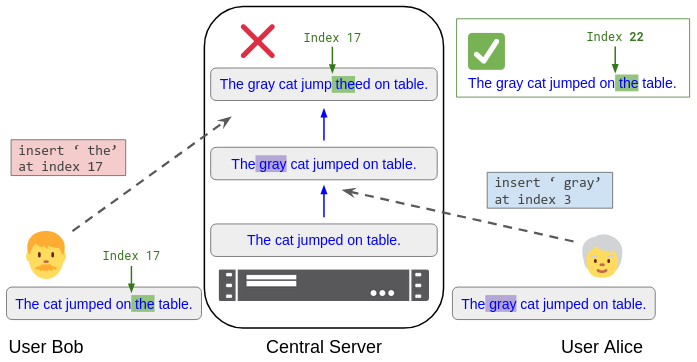
Figure 2. Bob submits the operation "insert ‘ the’ at index 17" to the central server. But before his edit arrives, the server applies Alice's concurrent operation "insert ‘ gray’ at index 3". So it no longer makes sense to apply Bob's operation at index 17; the server must "rebase" it to index 22.
This “index rebasing” challenge is best known for real-time collaborative apps like Google Docs, but technically, it can also affect non-real-time apps—e.g., a web form that inserts items into a list. The problem can even appear in single-threaded local apps, which need to transform text/list indices for features like annotations and edit histories.
Solutions to the index-rebasing problem fall into two camps:
-
Immutable Positions (CRDT-ish). Assign each character / list element an immutable ID that is ordered and moves around together with the character. I call these positions.
Fractional indexing is a simple example: assign each character a real number like 0.5, 0.75, 0.8, …; to insert a character between those at 0.5 and 0.75, use an operation like “add character
'x'at position 0.625”, which will end up in the right place even if the array index changes. Text/list CRDTs implement advanced versions of fractional indexing that avoid its main issues.Immutable positions are a good fit for CRDT-ish server-side rebasing, because the positions “make sense” as-is in newer states: you can always ask “what array index corresponds to this position right now?”.
-
Index Transformations (OT-ish). Directly transform index 17 to 22 in situations like Figure 2, by noticing that a concurrent operation inserted 5 characters in front of it. This is normal OT-ish server-side rebasing, but it is hard because there are a lot of edge cases—e.g., how do you transform an insert operation against a delete operation at the same index?
Typically, solutions to the index-rebasing problem are implemented as literal CRDT/OT algorithms inside of a full-stack CRDT/OT collaboration system. This can be quite restrictive, if you need the algorithms for text editing but otherwise want to make your own collaboration system (for custom server-side business logic, more control over the network and storage subsystems, etc.).
To alleviate these restrictions, I’m interested in tools that solve the index-rebasing problem using local data structures, independent of a specific collaboration system:
- For CRDT-ish systems, I created the list-positions library.
- For OT-ish systems, ProseMirror’s built-in rebasing function is a good example. ProseMirror’s author provides some perspective on why literal OT is overkill here.
Optimistic Local Updates
We now want to add real-time collaboration to our central server app. Recall that this means that users can see the effects of their own operations immediately, without waiting for a response from the server: their clients are allowed to perform optimistic local updates.
To incorporate optimistic local updates into our earlier abstract model, let us assume that each client has access to a reducer function à la Redux. It inputs a state and an operation, outputting the new state. This reducer function should emulate the server’s business logic, though it need not match exactly (e.g., it likely omits interactions with external systems).
Now we can define what we mean by “users can see the effects of their own operations immediately”. At any time, a user’s optimistic local state is given by:
- Start with the latest state received from the server.
- Apply the reducer function to all pending local operations—operations that were performed locally but not yet acknowledged by the server.
In other words, the optimistic local state is what the client thinks the server’s state will be once the server processes its local operations, assuming that there are no intervening concurrent operations, authorization issues, etc.
Processing local operations is easy; the client just needs to apply the reducer function. The interesting part is processing remote operations—state updates received from the server—in the presence of pending local operations:
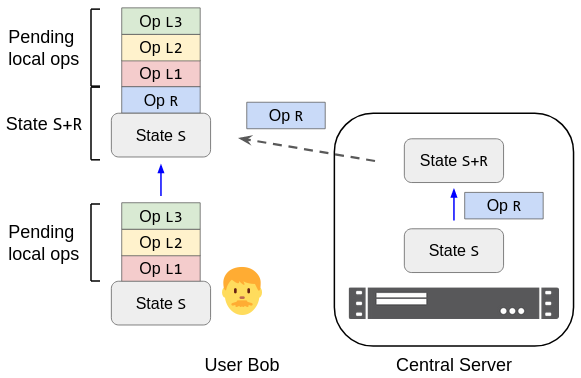
Figure 3. Bob's client optimistically renders the state S+L1+L2+L3, where S is the last state received from the server and L1, L2, L3 are pending local operations. After receiving a remote operation R from the server, his client must render the new optimistic state (S+R)+L1+L2+L3.
The three techniques below are different ways to update the client’s state in situations like Figure 3. Note that the correct answer is already specified by the abstract model above—the three techniques are merely different ways to compute it.
1. Server Reconciliation
One implementation technique is to take the abstract model literally: when a client receives a batch of remote operations from the server,
- Undo all pending local operations. This rewinds the state to the client’s previous view of the server’s state.
- Apply the remote operations. This brings the client up-to-date with the server’s state.
- Redo any pending local operations that are still pending, i.e., they were not acknowledged as part of the remote batch.
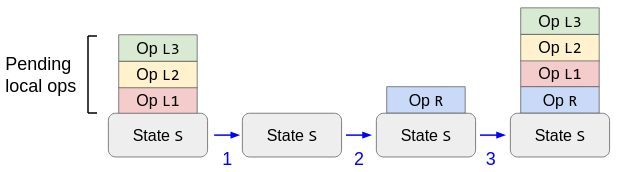
The Server Reconciliation way to process a remote operation R in the presence of pending local operations L1, L2, L3.
Step 1 could involve literal undo commands, using a local stack that records how to undo each pending local mutation. Or, you could store the app state as a persistent data structure and directly restore the state before the first pending local mutation. Or, the server could tell you the exact new state to use (= its own latest state), which you use directly as the result of step 2.
If you use OT-ish server-side rebasing—the server transforms operations received after concurrent operations—then you must apply an equivalent transformation to the pending local operations in step 3. Basically, ensure that the new log of pending local operations matches what the server would apply to its own state, if it received the original operations next.
This technique is called server reconciliation and has been used in multiplayer games since the 1990s. It is the most flexible way to implement optimistic local updates, since it works for arbitrary operations and business logic.
You do need special support from your local data structures to implement step 1—e.g., “undoable” or persistent data structures—but these are easier to implement than CRDT or OT data structures. Indeed, their special properties are purely local, so your data structures don’t need to reason about concurrency or eventual consistency. (Instead, “reasoning about concurrency” takes place during server-side rebasing.)
Because of its simplicity and flexibility, server reconciliation is where I’ve focused my own recent research efforts. However, undoing and redoing pending local operations does increase the cost of remote updates, which could cause performance issues. Let us now discuss two techniques that avoid this cost by applying remote operations to the state “directly”: literal CRDT and OT.
2. CRDT
The CRDT way to process a remote operation is: just process it directly, as if there were no pending local operations. This works because a new remote operation is always concurrent to all pending local operations, and (op-based) CRDTs guarantee that concurrent operations commute:
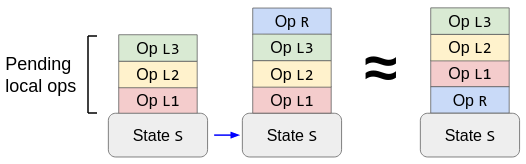
The CRDT way to process a remote operation R in the presence of pending local operations L1, L2, L3. The reordered operations are equivalent (same final states) because concurrent operations commute by assumption.
In some cases, clients can process a remote operation “directly” without using a literal CRDT. The example I have in mind is a key-value store with operations set(key, value) (used by Figma object properties):
- When a user performs a pending local operation, mark its key as “pending” on that user’s device. Unmark it once the operation is acknowledged by the server.
- To process a remote operation
set(key, value), first check ifkeyis marked pending. If so, do nothing; otherwise, setkeytovaluenormally. This is equivalent to re-applying pending local operations “on top” of the remote operation, as required by Figure 3.
CRDTs can be made quite efficient. For rich-text editing, which is a hard case, Yjs and Collabs can each support ~100 simultaneously active users with a modest server and clients, vs <32 for Google Docs (an OT system).
The downside is that you must restrict yourself to commuting concurrent operations, which are hard to come by. In practice, this means that apps often only use CRDTs provided by an expert-made library—though my blog tries to change that.
3. OT
The OT way to process a remote operation is: transform it into a new operation that has the same effect as server reconciliation, then apply the transformed operation to the optimistic local state.
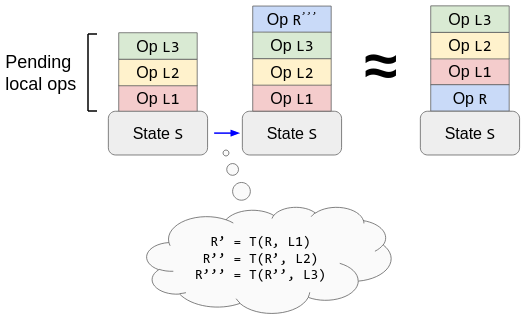
The OT way to process a remote operation R in the presence of pending local operations L1, L2, L3. The reordered operations are equivalent (same final states) by a property of T.
The downside is again that you must restrict yourself to specific operations: those possessing a transformation T that satisfies the algebraic rule Transformation Property 1 (TP1). I don’t know how difficult it is to find such functions in practice, but be warned that the number of transformation cases increases as O((# op types)^2). TP1 is at least easier to satisfy than Transformation Property 2 (TP2)—something that many text algorithms get wrong but that is only necessary for decentralized collaboration.
Discussion
Much work has gone into designing CRDT and OT algorithms, which are challenging because they must satisfy algebraic rules. I and others have also spent a lot of time thinking about how to structure apps so that they can tolerate CRDTs’ limited room for custom business logic.
Thus it is ironic to see that, in the centralized model used by this blog post, CRDTs and OT are merely optimizations over server reconciliation, which is straightforward and completely flexible. Moreover, CRDT/OTs’ usage by clients is unrelated to the app’s core collaboration logic, which instead takes place during server-side rebasing—a setting with no strict algebraic rules.
That said, the difficult parts of CRDTs/OT are still useful for decentralized collaboration (though see other options in the Appendix), and for making sense of collaborative text and list operations.
Form of Operations
The previous two sections each described an architectural challenge and options for how to address it. Before showing the choices made by existing apps and devtools, I want to introduce one more axis of variation:
Form of Operations. What is the form of the operations sent from clients to the server, and vice-versa? Are they high-level and app-specific (“pick up loot”), or low-level state changes (“set key K to value V”)?
1. Mutations
Most of my example operations so far have been high-level and app-specific: “pick up loot”, “mark task as completed”, “increment like count”, etc. I call these mutations, following Replicache.
Mutations give you maximum control over the behavior of server-side rebasing, allowing you to accommodate app-specific business logic and user intent. On the other hand, this also gives you the freedom to make mistakes, e.g., defining mutations that rebase weirdly or are expensive to process.
2. State Changes
Alternatively, operations can be low-level state changes sent between clients and the server. This is especially common with replicated databases (Firebase RTDB, ElectricSQL, Triplit, etc.): clients translate user actions into local database changes, and the database replicates those changes without knowing about the original user action.
Because state changes are often simple and reusable, they can be implemented by off-the-shelf tools and highly optimized. However, they hide information about the original user action from the server, making it harder for server-side rebasing to respect app-specific business logic and user intent.
Discussion
It’s possible to send mutations from the client to the server, but state changes from the server back to clients. Many multiplayer games work this way: clients send high-level user actions to the server (“walk-forward key is pressed”), which the server processes (applying collision detection etc.) and then translates into low-level world updates (“entity E moved to coordinates (x, y, z)”).
The dividing line between mutations and state changes is somewhat arbitrary. For example, operations on collaborative XML are high level (“format text”, “split node”), but they ignore specific apps’ schemas and user actions. Below, I place devtools in the “mutations” category only if apps can customize the contents of operations sent over the network.
Classification Table
We now have three high-level architectural choices when implementing this post’s abstract model of central server collaboration:
- Server-Side Rebasing. How the server makes sense of operations that arrive after concurrent operations.
- Optimistic Local Updates. How clients process remote operations when they have pending local operations.
- Form of Operations. The level and specificity of operations sent from clients → server and server → clients.
These are not the only architectural choices—e.g., there are various ways to filter redundant operations after a client reconnects to the server—but I consider these the main high-level choices. They generalize the well-known “CRDT vs OT” choice.
The table below classifies various collaborative apps and devtools according to which options they pick. I’ve aimed for good coverage of the different combinations instead of a thorough survey of apps/tools.
| Server-Side Rebasing | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Clients → Server | Mutations | State Changes | |||||||
| Server → Clients | Serializable | CRDT-ish | OT-ish | Serializable | CRDT-ish | OT-ish | |||
| Optimistic Local Updates | Mutations | Server Reconciliation | ProseMirror-collab | Actyx*, ProseMirror-log | ProseMirror-collab-commit | ||||
| CRDT | |||||||||
| OT | Google Docs | ||||||||
| State Changes | Server Reconciliation | Half-Life engine, Replicache | Automerge*, Fluid Framework | ||||||
| CRDT | Firebase RTDB, Yjs*, Triplit, ... | ||||||||
| OT | ShareDB | ||||||||
Notes:
- Tools marked with * also work in the absence of a central server.
- The red-shaded quadrant is ruled out, since if you send low-level state changes from clients to the server, it cannot convert them back into high-level mutations for sending to clients.
- The yellow-shaded cells seem impractical to me: once you’ve implemented CRDTs/OT for optimistic local updates, you might as well use them for server-side rebasing, too.
Conclusion
CRDT and OT algorithms are the classic approaches to real-time collaboration (in practice, mostly OT). When it comes to collaborative text and lists, this is understandable, since you will need some way to solve the index rebasing challenge. However, we’ve seen that literal CRDT/OT architectures are not the only option, and in fact they are likely overkill for a central server app:
- Server-side rebasing can be “CRDT-ish” or “OT-ish” instead of literal CRDT/OT. The real requirements are to respect your app’s business logic, and to attempt to match user expectations. (For text and lists, you can call out to local data structures that solve the index rebasing challenge.)
- Optimistic local updates must implement a specific abstract model (client state = server’s latest state + pending local operations), but this can be done for arbitrary operations and business logic using server reconciliation. Literal CRDT/OT algorithms allow for a more direct implementation but don’t change the user-visible behavior.
Going forward, I am interested in exploring the classification table’s Mutations/Mutations, CRDT-ish, Server Reconciliation cell. This architecture is related to event sourcing and has similar trade-offs. It fits my longstanding goal of taking CRDT (-ish) ideas and making them as flexible as possible: server reconciliation frees you from CRDTs’ algebraic rules, and mutations free you from the need to express state and operations in a particular form (e.g., as database changes). The architecture also seems well-suited for apps that want to support edit histories and perhaps even decentralized version control, as described in the appendix.
Acknowledgements
I thank AJ Nandi and Matt Wonlaw for feedback on a draft of this post, and James Addison and Matthew Linkous for insightful discussions.
Appendix: From Centralized to Decentralized
Our abstract model above assumed a central server. The server had two main tasks:
- Assign a total order to operations—namely, the order that the server receives them.
- Update the state in response to operations, using the app’s business logic.
Clients can already do the second task themselves, using the same reducer function as for optimistic local updates. (Techically, this gets tricky when your app’s business logic is nondeterministic or involves interactions with external systems, but let’s assume that your app does not have those issues.)
Then in principle, to create a decentralized version of your app, all you need is either:
- Clients that don’t care about the total order of operations
- Or, a decentralized way for clients to (eventually) agree on a total order of operations.
Literal CRDT/OT algorithms follow approach 1: they guarantee that all users will end up in the same state, regardless of the order in which they process operations. As noted already, though, this requires strict algebraic rules that are tricky to satisfy. (For decentralized OT, you must satisfy both TP1 and TP2.)
Approach 2 instead lets you use the more flexible server reconciliation technique (but without the server!). Note that for sanity, the total order on operations should be an extension of the causal order. There are a number of ways to eventually agree on a total order that extends the causal order:
- Assign each operation a logical timestamp when it is created and sort by those. (Ex: Automerge, Actyx)
- Use an arbitrary topological sort of the causal order. (Ex: Wonlaw 2023)
- Append operations to a list CRDT and use its list order. Often, this amounts to an over-engineered implementation of the previous idea.
- Use a topological sort informed by business logic, e.g., authorization rules. (Ex: Matrix)
With all of these techniques, it is technically possible for a client to receive an old operation that belongs arbitrarily far back in the log. So to permit server reconciliation, clients need to store the entire operation log indefinitely—not just the current state. You can mitigate this cost by using fancy compression and/or by putting the log in cold storage (disk/network).
Another idea is to let each client choose its own total order on operations, but keep clients roughly in sync by social convention. Git branches work this way: the computer doesn’t force you to update your local branches in any particular way, but you probably agree with your collaborators to occasionally download a canonical remote branch (git pull origin main) and add your own commits to the head of that branch (via merge/rebase). This is what I had in mind when I mentioned decentralized version control on top of the Mutations/Mutations, CRDT-ish, Server Reconciliation cell; Section 4 of my PhD thesis proposal explores the idea in more detail.
Home • Matthew Weidner • PhD student at CMU CSD • mweidner037 [at] gmail.com • @MatthewWeidner3 • LinkedIn • GitHub