Announcing list-positions
Matthew Weidner |
Apr 29th, 2024
Home | RSS Feed
Keywords: list-positions, collaborative text editing, Fugue
The main ideas in this post are described in slides here.
Motivation
Suppose you’re implementing a text editor. A key choice you must make is what data structure to use for the text. Traditionally, this is an array of characters, or an optimized equivalent like a rope. These data structures all implement a sequence abstraction: your mental model of the text is a map (index -> char).
In a sequence like this, insertions and deletions “shift” the indices of later characters. For example, if a user types “E-“ in front of the text “Bike route”, the index of “B” increases by 2:
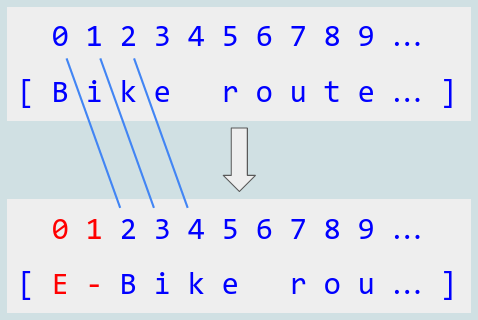
With that in mind, let’s consider various features that you might add to your text editor.
-
Comments. The user can add a comment to a range of text.
It’s easy to store each comment in the form
{ from: 40, to: 49, comment: "Or ..." }, wherefromandtoare indices indicating the range of text. But you’ll need to remember to updatefromandtowhenever future edits shift the text’s range. -
History and blame. The user can view how historical edits map to the current state, like with git blame.
You can compute blame from a log of changes like
{ op: "insert", index: 23, chars: "my house" }. However, it will take some effort to correlate the original insertion/deletion index with a character’s current index in the text, due to shifting caused by subsequent edits. -
Collaborative editing. Multiple users can collaborate on a text document.
An obvious strategy is to send edits like
Insert " the" at index 17to a central server, which applies them to its own copy of the text in receipt order. There is a problem you’ll need to address, though: By the time an edit makes it to the server, the server may have applied a concurrent edit from another user that invalidates its indices.
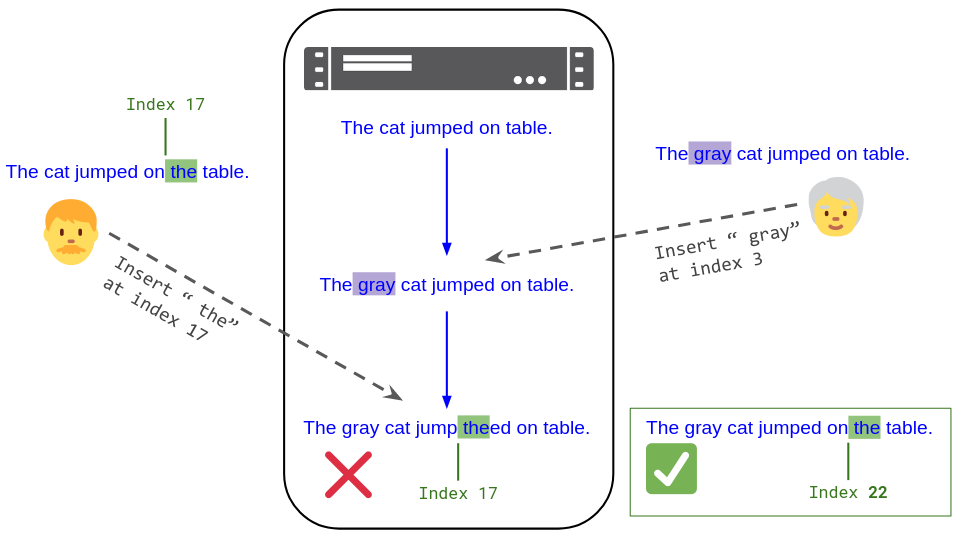
Bob submits the edit Insert " the" at index 17 to a central server. But before his edit arrives, the server applies Alice's concurrent edit Insert " gray" at index 3. So it no longer makes sense to apply Bob's edit at index 17; it must be shifted to index 22.
Overall, while implementing these features, you’re going to spend a lot of effort transforming array indices to account for other insertions and deletions. What if you could avoid this effort, by assigning each character an immutable identifier that’s always “in the right place”?
list-positions
list-positions is a new TypeScript library designed to do exactly that. It models text as an ordered map (position -> char), where each character’s position is unique, immutable, and totally ordered. So if you insert a new entry (position, char) into the map, the other entries stay the same, even though their array indices change:
Before:
Index | 0 1 2
Position | pos123 posLMN posXYZ
Value | 'C' 'a' 't'
After calling list.set(posABC, 'h') where pos123 < posABC < posLMN:
Index | 0 1 2 3
Position | pos123 posABC posLMN posXYZ
Value | 'C' 'h' 'a' 't'
More generally, you can use list-positions for lists of arbitrary values: items in a todo-list, spreadsheet rows and columns, slides in a slideshow, etc.
List-positions is a library of local data structures: it provides list-as-ordered-map types that you can manipulate however you like. However, lists on different devices can share positions, and positions are guaranteed to be unique and totally ordered even if they are generated concurrently on different devices. So you can use list-positions to implement collaborative lists and text, on top of a variety of network architectures.
For example, you can send edits to a central server like above, just using positions instead of array indices. Each position will be “in the right place” even if a concurrent edit arrives first:
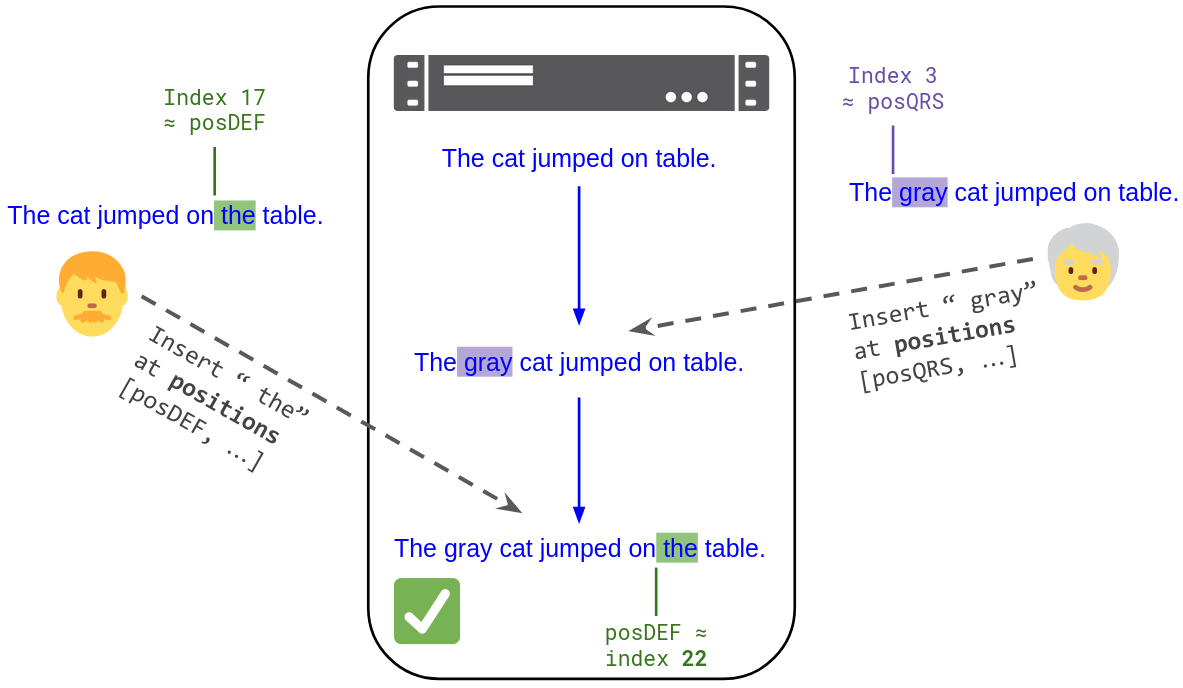
Alice and Bob submits edits to a central server like above, but this time, they use positions instead of array indices. When the server receives Bob's edit, it looks up the index corresponding to posDEF and finds that it is now 22. Thus Bob's text ends up in the right place.
Why This Library?
If you’ve read my previous blog posts, you probably expected me to announce a CRDT library - not a local data structures library. List-positions does indeed get its core algorithm from the Fugue list CRDT, and you can easily implement traditional list CRDTs on top of the library.
However, the motivation section above shows that immutable positions are not just for collaboration: they are a general way of thinking about sequences that help you implement single-user functionality as well. Collaboration is merely where the challenges of mutable array indices become too large to ignore. (Though you can make them work, using Operational Transformation.)
I’ll admit that my own motivation for list-positions comes from various collaboration-related problems. In particular, I could not figure out how to solve the following problems with traditional CRDTs:
- Server authority. If your collaborative app has a central server, it should be able to understand clients’ updates and choose to accept, modify, or reject them, like in a traditional CRUD app. This is tricky with existing CRDTs because their updates are often opaque binary blobs, and it is hard to “reject” an update without also rejecting all future updates from that client. With list-positions, you choose the format and meaning of network messages, and your server can choose exactly how to update its local data structures.
- Complex data types. Some data structures are just plain difficult to model as a CRDT. The example I have in mind is a ProseMirror document, which is an XML-like tree where users can split and merge nodes. Instead of figuring out a proper CRDT, you can just say “Apply everyone’s ProseMirror steps in a fixed order (e.g., a server’s receipt order)”, except that array indices will get messed up like above. By replacing the array indices with positions, I got a schema-agnostic ProseMirror collaboration prototype working in a few days.
- Cherry-picking. Git lets you “cherry-pick” updates from one branch to another, without also applying all previous updates. CRDTs struggle with this because their internal metadata assumes causality/monotonicity. With list-positions, you can manage metadata yourself, independent of user-visible changes. Thus with some setup, you can implement CRDT-style rich-text editing on top of git in a way that supports cherry-picking.
As an added bonus, separating the position abstraction from a particular sync strategy makes it possible to implement collaborative text/list editing on top of various data stores (without merely storing an append-only log of CRDT messages). That way, not every data store implementer needs to become an expert on list CRDTs/OT. For example, I’ve made prototypes of collaborative rich-text editing on top of the Triplit NoSQL DB, Replicache client-side sync framework, and ElectricSQL database sync service - see list-positions-demos.
Relative to my position-strings library, list-positions implements the same abstraction (unique immutable positions), but with actually practical performance for text and large lists. List-positions also has a more convenient, non-minimalist API. On the other hand, its positions are less portable than lexicographically-ordered strings.
Performance
Performance is always a concern for text-editing libraries that assign a unique immutable ID to each character. If you naively store each character’s ID as an object, you’ll have excessive memory usage and saved state sizes.
To avoid this, list-positions groups together “runs” of characters, similar to a rope. Like a rope, the runs form a tree, but unlike a rope, the tree is never rebalanced; that aids positions’ immutability. You can find more detail in internals.md.
The resulting performance is more than adequate in my (admittedly basic) benchmarks. E.g., constructing a traditional CRDT on top of the library and applying the automerge-perf 260k edit text trace gives the following results, which are competitive with state-of-the-art CRDT libraries on crdt-benchmarks B4:
- Sender time (ms): 655 (400k ops/sec)
- Avg update size (bytes): 92.7
- Receiver time (ms): 369 (700k ops/sec)
- Save time (ms): 11
- Save size (bytes): 599817 (Naive JSON encoding; 6x plain text size)
- Load time (ms): 10
- Save time GZIP'd (ms): 42
- Save size GZIP'd (bytes): 87006 (GZIP'd JSON encoding; 3x GZIP'd text size)
- Load time GZIP'd (ms): 30
- Mem used estimate (MB): 1.8 (<20 bytes/char)
Conclusion
There’s much more info in the docs: github.com/mweidner037/list-positions#readme.
You can also check out @list-positions/formatting, @list-positions/crdts, and list-positions-demos.
Going forward, I’d like to convert the demos into polished “bindings” for various rich-text editors, in the style of Yjs’s editor bindings. Let me know if you are interested in collaborating on this. I also welcome general questions or comments (preferably as issues).
Home • Matthew Weidner • Common Curriculum / CMU PhD student • mweidner037 [at] gmail.com • @MatthewWeidner3 • @mweidner.bsky.social • LinkedIn • GitHub