CRDT Survey, Part 1: Introduction
Matthew Weidner |
Sep 26th, 2023
Home | RSS Feed
Keywords: CRDTs, collaborative apps
This blog post is Part 1 of a series.
What is a CRDT?
Suppose you’re implementing a collaborative app. You’ve heard that Conflict-free Replicated Data Types (CRDTs) are a good fit and you want to know more about them.
If you look up the definition of CRDT, you will find that there are two main kinds, “op-based” and “state-based”, and these are defined using mathematical terms like “commutativity”, “semilattice”, etc. This is probably already more complicated than your mental model of a collaborative app, and I imagine it can be intimidating.
Let’s step back a bit and think about what you’re trying to accomplish.
In a collaborative app, users expect to see their own operations immediately, without waiting for a round-trip to a central server. This is especially true in a local-first app, where users can make edits even when they are offline, or when there is no central server.
Immediate local edits make it possible for users to perform operations concurrently: logically simultaneously, with no agreement on the order of operations. Those users will temporarily see different states. Eventually, though, they will synchronize with each other, combining their operations.
At that point, the collaborative app must decide: What is the state resulting from these concurrent operations? Because the operations were logically simultaneous, we shouldn’t just pretend that they happened in some sequential order. Instead, we need to combine them in a way that matches users’ expectations.
Example: Ingredient List
Here is a simple example. The app is a collaborative recipe editor (Collabs demo), which includes an ingredient list:

Suppose that:
- One user deletes the first ingredient (“Head of broccoli”).
- Concurrently, a second user edits “Oil” to read “Olive Oil”.
We could try broadcasting the non-collaborative version of these operations: Delete ingredient 0; Prepend "Olive " to ingredient 1. But if another user applies those operations literally in that order, they’ll end up with “Olive Salt”:

Instead, you need to interpret those operations in a concurrency-aware way: Prepend 'Olive' applies to the “Oil” ingredient regardless of its current index.

Semantics
In the above example, the users’ intended outcome was obvious. You can probably also anticipate how to implement this behavior: identify each ingredient by a unique ID instead of its index.
Other situations can be more interesting. For example, starting from the last recipe above, suppose the two users perform two more operations:
- The first user increases the amount of salt to 3 mL.
- Concurrently, the second user clicks a “Halve the recipe” button, which halves all amounts.
We’d like to preserve both users’ edits. Also, since it’s a recipe, the ratio of amounts is more important than their absolute values. Thus you should aim for the following result:
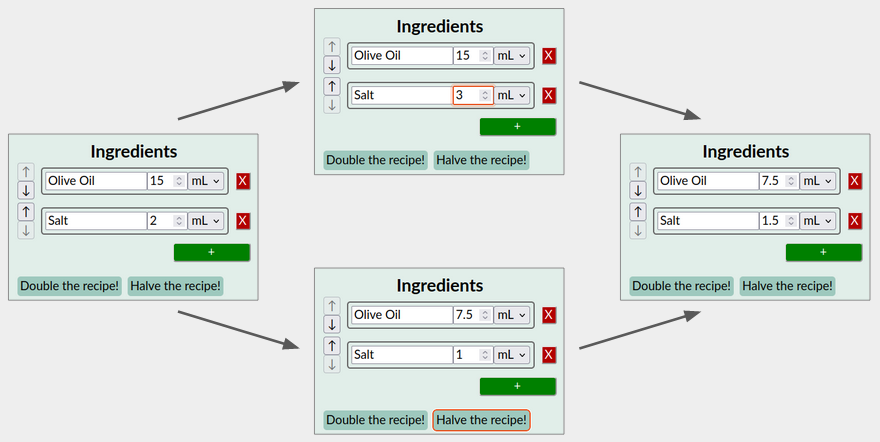
In general, a collaborative app’s semantics are an abstract description of what the app’s state should be, given the operations that users have performed. This state must be consistent across users: two users who are aware of the same operations must be in the same state.
Choosing an app’s semantics is more difficult than it sounds, because they must be well-defined in arbitrarily complex situations. For example, if a third user performs a bunch of operations concurrently to the four operations above, the collaborative recipe editor must still end up in some consistent state - hopefully one that makes sense to users.
Algorithms
Once you’ve chosen your collaborative app’s semantics, you need to implement them, using algorithms on each user device.
For example, suppose train conductors at different doors of a train count the number of passengers boarding. When a conductor sees a passenger board through their door, they increment the collaborative count. Increments don’t always synchronize immediately due to flaky internet; this is fine as long as all conductors eventually converge to the correct total count.
The app’s semantics are obvious: its state should be the number of increment operations so far, regardless of concurrency. Specifically, an individual conductor’s app will display the number of increment operations that it is aware of.
Op-Based CRDTs
Here is one algorithm that implements these semantics:
- Per-user state: The current count, initially 0.
- Operation
inc(): Broadcast a message+1to all devices. Upon receiving this message, each user increments their own state. (The initiator also processes the message, immediately.)
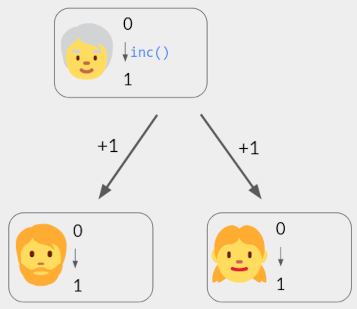
It is assumed that when a user broadcasts a message, it is eventually received by all collaborators, without duplication (i.e., exactly-once). For example, each user could send their messages to a server; the server stores these messages and forwards them to other users, who filter out duplicates.
Algorithms in this style are called op-based CRDTs. They work even if the network has unbounded delays or delivers messages in different orders to different users. Indeed, the above algorithm matches our chosen semantics even under those conditions.
State-Based CRDTs
Op-based CRDTs can also be used in peer-to-peer networks without any servers. However, usually each user needs to store a complete message history, in case another user requests old messages. (It is a good idea to let users forward each other’s messages, not just their own.) This has a high storage cost: O(total count) in our example app.
A state-based CRDT is a different kind of algorithm that sometimes reduces this storage cost. It consists of:
- A per-user state. Implicitly, this state encodes the set of operations that the user is aware of, but it is allowed to be a lossy encoding.
- For each operation (e.g.
inc()), a function that updates the local state to reflect that operation. - A merge function that inputs a second state and updates the local state to reflect the union of sets of operations:
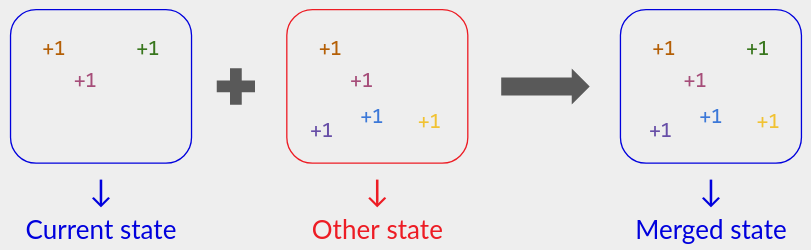
We’ll see an optimized state-based counter CRDT later in this blog series.
But briefly, instead of storing the complete message history, you store a map from each device to the number of inc() operations performed by that device. This encodes the operation history in a way that permits merging (entrywise max), but has storage cost O(# devices) instead of O(total count).
Unless you need state-based merging, the counting app doesn’t really require specialized knowledge - it just counts in the obvious way. But you can still talk about the “op-based counter CRDT” if you want to sound fancy.
Defining CRDTs
One way to define a CRDT is as “either an op-based CRDT or a state-based CRDT”. In practice, we can be more flexible. For example, CRDT libraries usually implement hybrid op-based/state-based CRDTs, which let you use both op-based messaging and state-based merging in the same app.
I like this broader, informal definition: A CRDT is a distributed algorithm that computes a collaborative app’s state from its operation history. This state must depend only on the operations that users have performed: it must be the same for all users that are aware of the same operations, and it must be computable without extra coordination or help from a single source-of-truth. (Message forwarding servers are okay, but you’re not allowed to put a central server in charge of the state like in a traditional web app.)
Of course, you can also use CRDT techniques even when you do have a central server. For example, a collaborative text editor could use a CRDT to manage the text, but a server DB to manage permissions.
Outline of this Survey
In this blog series, I will survey CRDT techniques for collaborative apps. My goal is to demystify and summarize the techniques I know about, so that you can learn them too without a PhD’s worth of effort.
The techniques are divided into two “topics”, corresponding to the sections above:
- Semantic techniques help you decide what a collaborative app’s state should be.
- Algorithmic techniques tell you how to compute that state efficiently.
Part 2 (the next post) covers semantic techniques; I’ll cover algorithmic techniques in Part 3.
Since I’m the lead developer for the Collabs CRDT library, I’ll also mention where various techniques appear in Collabs. You can find a summary in the Collabs docs.
This survey is opinionated: I omit or advise against techniques that I believe don’t translate well to collaborative apps. (CRDTs are also used in distributed data stores, which have different requirements.) I also can’t hope to mention every CRDT paper or topic area; for that, see crdt.tech. If you believe that I’ve treated a technique unfairly - including your own! - please feel free to contact me: mweidner037 [at] gmail.com.
I thank Martin Kleppmann, Jake Teton-Landis, and Florian Jacob for feedback on portions of this survey. Any mistakes or bad ideas are my own.
Sources
I’ll cite specific references in-line, but here are some sources of general inspiration.
- Pure Operation-Based Replicated Data Types, Carlos Baquero, Paulo Sergio Almeida, and Ali Shoker (2017).
- How Figma’s multiplayer technology works, Evan Wallace (2019)
- Tackling Consistency-related Design Challenges of Distributed Data-Intensive Systems - An Action Research Study, Susanne Braun, Stefan Deßloch, Eberhard Wolff, Frank Elberzhager, and Andreas Jedlitschka (2021).
- A Framework for Convergence, Matt Wonlaw (2023).
This blog post is Part 1 of a series.
Home • Matthew Weidner • Common Curriculum / CMU PhD student • mweidner037 [at] gmail.com • @MatthewWeidner3 • @mweidner.bsky.social • LinkedIn • GitHub