CRDT Survey, Part 3: Algorithmic Techniques
Matthew Weidner |
Feb 13th, 2024
Home | RSS Feed
Keywords: CRDTs, optimization, state-based CRDTs
This blog post is Part 3 of a series.
Algorithmic Techniques
Let’s say you have chosen your collaborative app’s semantics in style of Part 2. That is, you’ve chosen a pure function that inputs an operation history and outputs the intended state of a user who is aware of those operations.
Here is a simple protocol to turn those semantics into an actual collaborative app:
- Each user’s state is a literal operation history, i.e., a set of operations, with each operation labeled by a Unique ID (UID).
- When a user performs an operation, they generate a new UID, then add the pair
(id, op)to their local operation history. - To synchronize their states, users share the pairs
(id, op)however they like. For example, users could broadcast pairs as soon as they are created, periodically share entire histories peer-to-peer, or run a clever protocol to send a peer only the pairs that it is missing. Recipients always ignore redundant pairs (duplicate UIDs). - Whenever a user’s local operation history is updated - either by a local operation or a remote message - they apply the semantics (pure function) to their new history, to yield the current app-visible state.
Technicalities:
- It is the translated operations that get stored in operation histories and sent over the network. E.g., convert list indices to list CRDT positions before storing & sending.
- The history should also include causal ordering metadata - the arrows in Part 2’s operation histories. When sharing an operation, also share its incoming arrows, i.e., the UIDs of its immediate causal predecessors.
- Optionally enforce causal order delivery, by waiting to add a received operation to your local operation history until after you have added all of its immediate causal predecessors.
This post describes CRDT algorithmic techniques that help you implement more efficient versions of the simple protocol above. We start with some Prerequisites that are also useful in general distributed systems. Then Sync Strategies describes the traditional “types” of CRDTs - op-based, state-based, and others - and how they relate to the simple protocol.
The remaining sections describe specific algorithms. These algorithms are largely independent of each other, so you can skip to whatever interests you. Misc Techniques fills in some gaps from Part 2, e.g., how to generate logical timestamps. Optimized CRDTs describes nontrivial optimized algorithms, including classic state-based CRDTs.
Table of Contents
Prerequisites
Replicas and Replica IDs
A replica is a single copy of a collaborative app’s state, in a single thread on a single device. For web-based apps, there is usually one replica per browser tab; when the user (re)loads a tab, a new replica is created.
You can also call a replica a client, session, actor, etc. However, a replica is not synonymous with a device or a user. Indeed, a user can have multiple devices, and a device can have multiple independently-updating replicas - for example, a user may open the same collaborative document in multiple browser tabs.
In previous posts, I often said “user” out of laziness - e.g., “two users concurrently do X and Y”. But technically, I always meant “replica” in the above sense. Indeed, a single user might perform concurrent operations across different devices.
The importance of a replica is that everything inside a replica happens in a sequential order, without any concurrency between its own operations. This is the fundamental principle behind the next two techniques.
It is usually convenient to assign each replica a unique replica ID (client ID, session ID, actor ID), by generating a random string when the replica is created. The replica ID must be unique among all replicas of the same collaborative state, including replicas created concurrently, which is why they are usually random instead of “the highest replica ID so far plus 1”. Random UUIDs (v4) are a safe choice. You can potentially use fewer random bits (shorter replica IDs) if you are willing to tolerate a higher chance of accidental non-uniqueness (cf. the birthday problem).
For reference, a UUID v4 is 122 random bits, a Collabs
replicaIDis 60 random bits (10 base64 chars), and a YjsclientIDis 32 random bits (a uint32).
Avoid the temptation to reuse a replica ID across replicas on the same device, e.g., by storing it in window.localStorage. That can cause problems if the user opens multiple tabs, or if there is a crash failure and the old replica did not record all of its actions to disk.
In Collabs: ReplicaIDs
Unique IDs: Dots
Recall from Part 2 that to refer to a piece of content, you should assign it an immutable Unique ID (UID). UUIDs work, but they are long (32 chars) and don’t compress well.
Instead, you can use dot IDs: pairs of the form (replicaID, counter), where counter is a local variable that is incremented each time. So a replica with ID "n48BHnsi" uses the dot IDs ("n48BHnsi", 1), ("n48BHnsi", 2), ("n48BHnsi", 3), …
In pseudocode:
// Local replica ID.
const replicaID = <sufficiently long random string>;
// Local counter value (specific to this replica). Integer.
let counter = 0;
function newUID() {
counter++;
return (replicaID, counter);
}
The advantage of dot IDs is that they compress well together, either using plain GZIP or a dot-aware encoding. For example, a vector clock (below) represents a sequence of dots ("n48BHnsi", 1), ("n48BHnsi", 2), ..., ("n48BHnsi", 17) as the single map entry { "n48BHnsi": 17 }.
You have some flexibility for how you assign the counter values. For example, you can use a logical clock value instead of a counter, so that your UIDs are also logical timestamps for LWW. Or, you can use a separate counter for each component CRDT in a composed construction, instead of one for the whole replica. The important thing is that you never reuse a UID in the same context, where the two uses could be confused.
Example: An append-only log could choose to use its own counter when assigning events’ dot IDs. That way, it can store its state as a Map<ReplicaID, T[]>, mapping each replica ID to an array of that replica’s events indexed by (counter - 1). If you instead used a counter shared by all component CRDTs, then the arrays could have gaps, making a Map<ReplicaID, Map<number, T>> preferable.
In previous blog posts, I called these “causal dots”, but I cannot find that name used elsewhere; instead, CRDT papers just use “dot”.
Collabs: Each transaction has an implicit dot ID (senderID, senderCounter).
Refs: Preguiça et al. 2010
Tracking Operations: Vector Clocks 1
Vector clocks are a theoretical technique with multiple uses. In this section, I’ll focus on the simplest one: tracking a set of operations. (Vector Clocks 2 is later.)
Suppose a replica is aware of the following operations - i.e., this is its current local view of the operation history:

I’ve labeled each operation with a dot ID, like ("A84nxi", 2).
In the future, the replica might want to know which operations it is already aware of. For example:
- When the replica receives a new operation in a network message, it will look up whether it has already received that operation, and if so, ignore it.
- When a replica syncs with another collaborator (or a storage server), it might first send a description of the operations it’s already aware of, so that the collaborator can skip sending redundant operations.
One way to track the operation history is to store the operations’ unique IDs as a set: { ("A84nxi", 1), ("A84nxi", 2), ("A84nxi", 3), ("A84nxi", 4), ("bu2nVP", 1), ("bu2nVP", 2)}. But it is cheaper to store the “compressed” representation
{
"A84nxi": 4,
"bu2nVP": 2
}
This representation is called a vector clock. Formally, a vector clock is a Map<ReplicaID, number> that sends a replica ID to the maximum counter value received from that replica, where each replica assigns counters to its own operations in order starting at 1 (like a dot ID). Missing replica IDs implicitly map to 0: we haven’t received any operations from those replicas. The above example shows that a vector clock efficiently summarizes a set of operation IDs.
The previous paragraph implicitly assumes that you process operations from each other replica in order: first
("A84nxi", 1), then("A84nxi", 2), etc. That always holds when you enforce causal-order delivery. If you don’t, then a replica’s counter values might have gaps (1, 2, 4, 7, ...); you can still encode those efficiently, using a run-length encoding, or a vector clock plus a set of “extra” dot IDs (known as a dotted vector clock).
Like dot IDs, vector clocks are flexible. For example, instead of a per-replica counter, you could store the most recent logical timestamp received from each replica. That is a reasonable choice if each operation already contains a logical timestamp for LWW.
Collabs: CausalMessageBuffer
Refs: Baquero and Preguiça 2016; Wikipedia
Sync Strategies
We now turn to sync strategies: ways to keep collaborators in sync with each other, so that they eventually see the same states.
Op-Based CRDTs
An operation-based (op-based) CRDT keeps collaborators in sync by broadcasting operations as they happen. This sync strategy is especially useful for live collaboration, where users would like to see each others’ operations quickly.
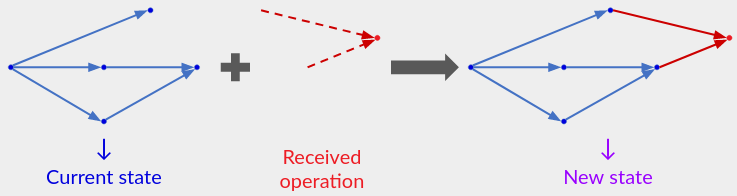
In the simple protocol at the top of this post, a user processes an individual operation by adding it to their operation history, then re-running the semantic function to update their app-visible state. An op-based CRDT instead stores a state that is (usually) smaller than the complete operation history, but it still contains enough information to render the app-visible state, and it can be updated incrementally in response to a received operation.
Example: The op-based counter CRDT from Part 1 has an internal state that is merely the current count. When a user receives (or performs) an inc() operation, they increment the count.
Formally, an op-based CRDT consists of:
- A set of allowed CRDT states that a replica can be in.
- A query that returns the app-visible state. (The CRDT state often includes extra metadata that is not visible to the rest of the app, such as LWW timestamps.)
- For each operation (
insert,set, etc.):- A
preparefunction that inputs the operation’s parameters and outputs a message describing that operation. An external protocol promises to broadcast this message to all collaborators. (Usually this message is just the translated form of the operation.prepareis allowed to read the current state but not mutate it.) - An
effectfunction that processes a message, updating the local state. An external protocol promises to calleffect:- Immediately for each locally-prepared message, so that local operations update the state immediately.
- Eventually for each remotely-prepared message, exactly once and (optionally) in causal order.
- A
In addition to updating their internal state, CRDT libraries’
effectfunctions usually also emit events that describe how the state changed. Cf. Views in Part 2.
To claim that an op-based CRDT implements a given CRDT semantics, you must prove that the app-visible state always equals the semantics applied to the set of operations effected so far.
As an example, let’s repeat the op-based unique set CRDT from Part 2.
- Per-user CRDT state: A set of pairs
(id, x).- Query: Return the CRDT state directly, since in this case, it coincides with the app-visible state.
- Operation
add:
prepare(x): Generate a new UIDid, then return the message("add", (id, x)).effect("add", (id, x)): Add(id, x)to your local state.- Operation
delete:
prepare(id): Return the message("delete", id).effect("delete", id): Delete the pair with the givenidfrom your local state, if it is still present.It is easy to check that this op-based CRDT has the desired semantics: at any time, the query returns the set of pairs
(id, x)such that you have an effected anadd(id, x)operation but nodelete(id)operations.Observe that the CRDT state is a lossy representation of the operation history: we don’t store any info about
deleteoperations or deletedaddoperations.
How can the “external protocol” (i.e., the rest of the app) guarantee that messages are effected at-most-once and in causal order? Using a history-tracking vector clock:
- On each replica, store a vector clock tracking the operations that have been effected so far.
- When a replica asks to send a prepared message, attach a new dot ID to that message before broadcasting it. Also attach the dot IDs of its immediate causal predecessors.
- When a replica receives a message:
- Check if its dot ID is redundant, according to the local vector clock. If so, stop.
- Check if the immediate causal predecessors’ dot IDs have been effected, according to the local vector clock. If not, block until they are.
- Deliver the message to
effectand update the local vector clock. Do the same for any newly-unblocked messages.
To ensure that messages are eventually delivered at-least-once to each replica (the other half of exactly-once), you generally need some help from the network. E.g., have a server store all messages and retry delivery until every client confirms receipt.
As a final note, suppose that two users concurrently perform operations o and p. You are allowed to deliver their op-based messages to effect in either order without violating the causal-order delivery guarantee. Semantically, the two delivery orders must result in equivalent internal states: both results correspond to the same operation history, containing both o and p. Thus for an op-based CRDT, concurrent messages commute.
Conversely, you can prove that if an algorithm has the API of an op-based CRDT and concurrent messages commute, then its behavior corresponds to some CRDT semantics (i.e., some pure function of the operation history). This leads to the traditional definition of an op-based CRDT in terms of commuting concurrent operations. Of course, if you only prove commutativity, there is no guarantee that the corresponding semantics are reasonable in the eyes of your users.
Collabs: sendCRDT and receiveCRDT in PrimitiveCRDT
Refs: Shapiro et al. 2011a
State-Based CRDTs
A state-based CRDT keeps users in sync by occasionally exchanging entire states, “merging” their operation histories. This sync strategy is useful in peer-to-peer networks (peers occasionally exchange states in order to bring each other up-to-date) and for the initial sync between a client and a server (the client merges its local state with the server’s latest state, and vice-versa).
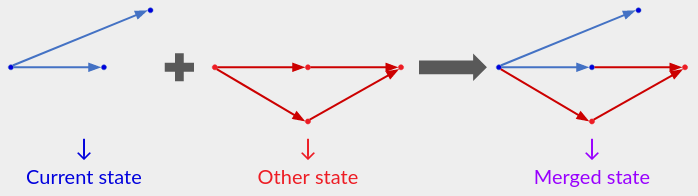
In the simple protocol at the top of this post, the “entire state” is the literal operation history, and merging is just the set-union of operations (using the UIDs to filter duplicates). A state-based CRDT instead stores a state that is (usually) smaller than the complete operation history, but it still contains enough information to render the app-visible state, and it can be “merged” with another state.
Formally, a state-based CRDT consists of:
- A set of allowed CRDT states that a replica can be in.
- A query that returns the app-visible state. (The CRDT state often includes extra metadata that is not visible to the rest of the app, such as LWW timestamps.)
- For each operation, a state mutator that updates the local state.
- A merge function that inputs two states and outputs a “merged” state. The app using the CRDT may set
local state = merge(local state, other state)at any time, where theother stateusually comes from a remote collaborator or storage.
To claim that a state-based CRDT implements a given CRDT semantics, you must prove that the app-visible state always equals the semantics applied to the set of operations that contribute to the current state. Here an operation “contributes” to the output of its state mutator, plus future states resulting from that state (e.g., the merge of that state with another).
As an example, let’s repeat just the state-based part of the LWW Register from Part 2.
- Per-user state:
state = { value, time }, wheretimeis a logical timestamp.- Query: Return
state.value.- Operation
set(newValue): Setstate = { value: newValue, time: newTime }, wherenewTimeis the current logical time.- Merge in other state: Pick the state with the greatest logical timestamp. That is, if
other.time > state.time, setstate = other.It is easy to check that this state-based CRDT has the desired semantics: at any time, the query returns the value corresponding to the
setoperation with the greatest logical timestamp that contributes to the current state.
As a final note, observe that for any CRDT states s, t, u, the following algebraic rules hold, because the same set of operations contributes to both sides of each equation:
- (Idempotence)
merge(s, s) = s. - (Commutativity)
merge(s, t) = merge(t, s). - (Associativity)
merge(s, (merge(t, u))) = merge(merge(s, t), u).
Thus for a state-based CRDT, the merge function is Associative, Commutative, and Idempotent (ACI).
Conversely, you can prove that if an algorithm has the API of a state-based CRDT and it satisfies ACI, then its behavior corresponds to some CRDT semantics (i.e., some pure function of the operation history). This leads to the traditional definition of a state-based CRDT in terms of an ACI merge function. Of course, if you only prove these algebraic rules, there is no guarantee that the corresponding semantics are reasonable in the eyes of your users.
Collabs: saveCRDT and loadCRDT in PrimitiveCRDT
Refs: Shapiro et al. 2011a
Other Sync Strategies
In a real collaborative app, it is inconvenient to choose op-based or state-based synchronization. Instead, it’s nice to use both, potentially within the same session.
Example: When the user launches your app, first do a state-based sync with a storage server to become in sync. Then use op-based messages over TCP to stay in sync until the connection drops.
Thus hybrid op-based/state-based CRDTs that support both sync strategies are popular in practice. Typically, these look like either state-based CRDTs with op-based messages tacked on (Yjs, Collabs), or they use an op-based CRDT alongside a complete operation history (Automerge).
To perform a state-based merge in the latter approach, you look through the received state’s history for operations that are not already in your history, and deliver those to the op-based CRDT. This approach is simple, and it comes with a built-in version history, but it requires more effort to make efficient (as Automerge has been pursuing).
Other sync strategies use optimized peer-to-peer synchronization. Traditionally, peer-to-peer synchronization uses state-based CRDTs: each peer sends a copy of its own state to the other peer, then merges in the received state. This is inefficient if the states overlap a lot - e.g., the two peers just synced one minute ago and have only updated their states slightly since then. Optimized protocols like Yjs’s sync potocol or Byzantine causal broadcast instead use back-and-forth messages to determine what info the other peer is missing and send just that.
For academic work on hybrid or optimized sync strategies, look up delta-state based CRDTs (also called delta CRDTs). These are like hybrid CRDTs, with the added technical requirement that op-based messages are themselves states (in particular, they are input to the state-based merge function instead of a separate
effectfunction). Note that some papers focus on novel sync strategies, while others focus on the orthogonal problem of how to tolerate non-causally-ordered messages.
Collabs: Updates and Sync - Patterns
Refs: Yjs document updates; Almeida, Shoker, and Baquero 2016; Enes et al. 2019
Misc Techniques
The rest of this post describes specific algorithms. We start with miscellaneous techniques that are needed to implement some of the semantics from Part 2: two kinds of logical timestamps for LWW, and ways to query the causal order. These are all traditional distributed systems techniques that are not specific to CRDTs.
LWW: Lamport Timestamps
Recall that you should use a logical timestamp instead of wall-clock time for Last-Writer Wins (LWW) values. A Lamport timestamp is a simple and common logical timestamp, defined by:
- Each replica stores a clock value
time, an integer that is initially 0. - Whenever you perform an LWW
setoperation, incrementtimeand attach its new value to the operation, as part of a pair(time, replicaID). This pair is called a Lamport timestamp. - Whenever you receive a Lamport timestamp from another replica as part of an operation, set
time = max(time, received time). - The total order on Lamport timestamps is given by:
(t1, replica1) < (t2, replica2)ift1 < t2or (t1 = t2andreplica1 < replica2). That is, the operation with a greater time “wins”, with ties broken using an arbitrary order on replica IDs.

Figure 1. An operation history with each operation labeled by a Lamport timestamp.
Lamport timestamps have two important properties (mentioned in Part 2):
- If
o < pin the causal order, then(o's Lamport timestamp) < (p's Lamport timestamp). Thus a new LWWsetalways wins over all causally-priorsets.- Note that the converse does not hold: it’s possible that
(q's Lamport timestamp) < (r's Lamport timestamp)butqandrare concurrent.
- Note that the converse does not hold: it’s possible that
- Lamport timestamps created by different users are always distinct (because of the
replicaIDtiebreaker). Thus the winner is never ambiguous.
Collabs: lamportTimestamp
Refs: Lamport 1978; Wikipedia
LWW: Hybrid Logical Clocks
Hybrid logical clocks are another kind of logical timestamp that combine features of Lamport timestamps and wall-clock time. I am not qualified to write about these, but Jared Forsyth gives a readable description here: https://jaredforsyth.com/posts/hybrid-logical-clocks/.
Querying the Causal Order: Vector Clocks 2
One of Part 2’s “Other Techniques” was Querying the Causal Order. For example, an access-control CRDT could include a rule like “If Alice performs an operation but an admin banned her concurrently, then treat Alice’s operation as if it had not happened”.
I mentioned in Part 2 that I find this technique too complicated for practical use, except in some special cases. Nevertheless, here are some ways to implement causal-order queries.
Formally, our goal is: given two operations o and p, answer the query “Is o < p in the causal order?”. More narrowly, a CRDT might query whether o and p are concurrent, i.e., neither o < p nor p < o.
Recall from above that a vector clock is a map that sends a replica ID to the maximum counter value received from that replica, where each replica assigns counters to its own operations in order starting at 1 (like a dot ID). Besides storing a vector clock on each replica, we can also attach a vector clock to each operation: namely, the sender’s vector clock at the time of sending. (The sender’s own entry is incremented to account for the operation itself.)

Figure 2. An operation history with each operation labeled by its dot ID (blue italics) and vector clock (red normal text).
Define a partial order on vector clocks by: v < w if for every replica ID r, v[r] <= w[r], and for at least one replica ID, v[r] < w[r]. (If r is not present in a map, treat its value as 0.) Then it is a classic result that the causal order on operations matches the partial order on their vector clocks. Thus storing each operation’s vector clock lets you query the causal order later.
Example: In the above diagram, { A84nxi: 1, bu2nVP: 1 } < { A84nxi: 4, bu2nVP: 2 }, matching the causal order on their operations. Meanwhile, { A84nxi: 1, bu2nVP: 1 } and { A84nxi: 2 } are incomparable, matching the fact that their operations are concurrent.
Often you only need to query the causal order on new operations. That is, you just received an operation p, and you want to compare it to an existing operation o. For this, it suffices to know o’s dot ID (replicaID, counter): If counter <= p.vc[replicaID], then o < p, else they are concurrent. Thus in this case, you don’t need to store each operation’s vector clock, just their dot IDs (though you must still send vector clocks over the network).
The above discussion changes slightly if you do not assume causal order delivery. See Wikipedia’s update rules.
We have a performance problem: The size of a vector clock is proportional to the number of past replicas. In a collaborative app, this number tends to grow without bound: each browser tab creates a new replica, including refreshes. Thus if you attach a vector clock to each op-based message, your network usage also grows without bound.
Some workarounds:
- Instead of attaching the whole vector clock to each op-based message, just attached the UIDs of the operation’s immediate causal predecessors. (You are probably attaching these anyway for causal-order delivery.) Then on the receiver side, look up the predecessors’ vector clocks in your stored state, take their entry-wise max, add one to the sender’s entry, and store that as the operation’s vector clock.
- Same as 1, but instead of storing the whole vector clock for each operation, just store its immediate causal predecessors - the arrows in the operation history. This uses less space, and it still contains enough information to answer causal order queries:
o < pif and only if there is a path of arrows fromotop. However, I don’t know of a way to perform those queries quickly. - Instead of referencing the causal order directly, the sender can list just the “relevant”
o < pas part ofp’s op-based message. For example, when you set the value of a multi-value register, instead of using a vector clock to indicate whichset(x)operations are causally prior, just list the UIDs of the current multi-values (cf. the multi-value register on top of a unique set).
Collabs: vectorClock
Refs: Baquero and Preguiça 2016; Wikipedia; Automerge issue discussing workarounds
Optimized CRDTs
We now turn to optimizations. I focus on algorithmic optimizations that change what state you store and how you access it, as opposed to low-level code tricks. Usually, the optimizations reduce the amount of metadata that you need to store in memory and on disk, at least in the common case.
These optimizations are the most technical part of the blog series. You may wish to skip them for now and come back only when you are implementing one, or trust someone else to implement them in a library.
List CRDTs
I assume you’ve understood Lists and Text Editing from Part 2.
There are too many list CRDT algorithms and optimizations to survey here, but I want to briefly introduce one key problem and solution.
When you use a text CRDT to represent a collaborative text document, the easy way to represent the state is as an ordered map (list CRDT position) -> (text character). Concretely, this map could be a tree with one node per list CRDT position, like in Fugue: A Basic List CRDT.
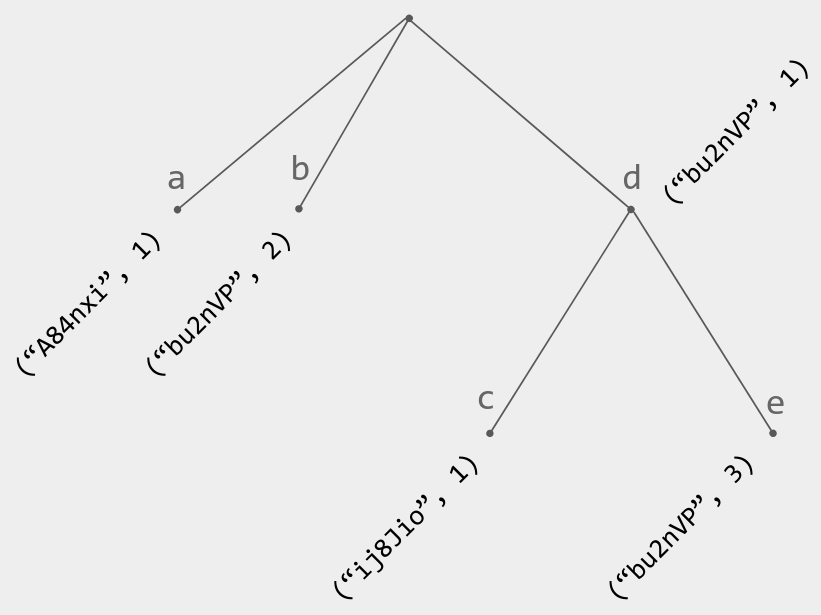
Figure 3. Example of a Fugue tree with corresponding text "abcde". Each node's UID is a dot.
In such a tree, each tree node contains at minimum (1) a UID and (2) a pointer to its parent node. That is a lot of metadata for a single text character! Plus, you often need to store this metadata even for deleted characters (tombstones).
Here is an optimization that dramatically reduces the metadata overhead in practice:
- When a replica inserts a sequence of characters from left to right (the common case), instead of creating a new UID for each character, only create a UID for the leftmost character.
- Store the whole sequence as a single object
(id, parentId etc, [char0, char1, ..., charN]). So instead of one tree node per character, your state has one tree node per sequence, storing an array of characters. - To address individual characters, use list CRDT positions of the form
(id, 0),(id, 1), …,(id, N).
It’s possible to later insert characters in the middle of a sequence, e.g., between char1 and char2. That’s fine; the new characters just need to indicate the corresponding list CRDT positions (e.g. “I am a left child of (id, 2)”).
Applying this optimization to Fugue gives you trees like so, where only the filled nodes are stored explicitly (together with their children’s characters):
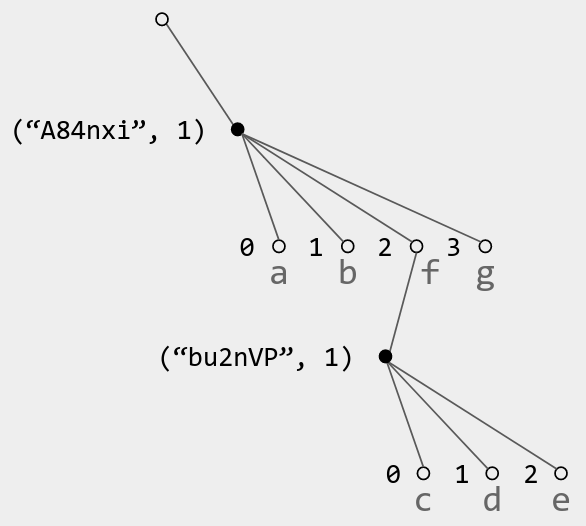
Figure 4. Example of an optimized Fugue tree with corresponding text "abcdefg".
Collabs: Waypoints in CTotalOrder
Refs: Yu 2012; Jahns 2020 (Yjs blog post)
Formatting Marks (Rich Text)
Recall the inline formatting CRDT from Part 2. Its internal CRDT state is an append-only log of formatting marks
type Mark = {
key: string;
value: any;
timestamp: LogicalTimestamp;
start: { pos: Position, type: "before" | "after" }; // type Anchor
end: { pos: Position, type: "before" | "after" }; // type Anchor
}
Its app-visible state is the view of this log given by: for each character c, for each format key key, find the mark with the largest timestamp satisfying
mark.key = key, and- the interval
(mark.start, mark.end)containsc’s position.
Then c’s format value at key is mark.value.
For practical use, we would like a view that represents the same state but uses less memory. In particular, instead of storing per-character formatting info, it should look more like a Quill delta. E.g., the Quill delta representing “Quick brown fox” is
{
ops: [
{ insert: "Quick " },
{ insert: "brow", attributes: { bold: true, italic: true } },
{ insert: "n fox", attributes: { italic: true } }
]
}
Here is such a view. Its state is a map: Map<Anchor, Mark[]>, given by:
- For each
anchorthat appears as thestartorendof any mark in the log,- The value at
anchorcontains pointers to all marks that start at or strictly contain anchor. That is,{ mark in log | mark.start <= anchor < mark.end }.
- The value at
Given this view, it is easy to look up the format of any particular character. You just need to go left until you reach an anchor that is in map, then interpret map.get(anchor) in the usual way: for each key, find the LWW winner at key and use its value. (If you reach the beginning of the list, the character has no formatting.)
I claim that with sufficient coding effort, you can also do the following tasks efficiently:
- Convert the whole view into a Quill delta or similar rich-text-editor state.
- Update the view to reflect a new mark added to the log.
- After updating the view, emit events describing what changed, in a form like Collabs’s RichTextFormatEvent:
type RichTextFormatEvent = {
// The formatted range is [startIndex, endIndex).
startIndex: number;
endIndex: number;
key: string;
value: any; // null if unformatted
previousValue: any;
// The range's complete new format.
format: { [key: string]: any };
}
Let’s briefly discuss Task 2; there’s more detail in the Peritext essay. When a new mark mark is added to the log:
- If
mark.startis not present inmap, go to the left of it until you reach an anchorprevthat is inmap, then domap.set(mark.start, copy of map.get(prev)). (If you reach the beginning of the list, domap.set(mark.start, []).) - If
mark.endis not present inmap, do likewise. - For each entry
(anchor, array)inmapsuch thatmark.start <= anchor < mark.end, appendmarktoarray.
Some variations on this section:
- Collabs represents the
Map<Anchor, Mark[]>literally using a LocalList - a local data structure that lets you build an ordered map on top of a separate list CRDT’s positions. Alternatively, you can store eachMark[]inline with the list CRDT, at its anchor’s location; that is how the Peritext essay does it. - When saving the state to disk, you can choose whether to save the view, or forget it and recompute it from the mark log on next load. Likewise for state-based merging: you can try to merge the views directly, or just process the non-redundant marks one at a time.
- In each
mapvalue (aMark[]), you can safely forget marks that have LWW-lost to another mark in the same array. Once a mark has been deleted from everymapvalue, you can safely forget it from the log.
Collabs: CRichText; its source code shows all three tasks
Refs: Litt et al. 2021 (Peritext)
State-Based Counter
The easy way to count events in a collaborative app is to store the events in an append-only log or unique set. This uses more space than the count alone, but you often want that extra info anyway - e.g., to display who liked a post, in addition to the like count.
Nonetheless, the optimized state-based counter CRDT is both interesting and traditional, so let’s see it.
The counter’s semantics are as in Part 1’s passenger counting example: its value is the number of +1 operations in the history, regardless of concurrency.
You can obviously achieve this semantics by storing an append-only log of +1 operations. To merge two states, take the union of log entries, skipping duplicate UIDs.
In other words, store the entire operation history, following the simple protocol from the top of this post.
Suppose the append-only log uses dot IDs as its UIDs. Then the log’s state will always look something like this:
[
((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1"), ((a6X7fx, 3), "+1"), ((a6X7fx, 4), "+1"),
((bu91nD, 1), "+1"), ((bu91nD, 2), "+1"), ((bu91nD, 3), "+1"),
((yyn898, 1), "+1"), ((yyn898, 2), "+1")
]
You can compress this state by storing, for each replicaID, only the range of dot IDs received from that replica. For example, the above log compresses to
{
a6X7fx: 4,
bu91nD: 3,
yyn898: 2
}
This is the same trick we used in Vector Clocks 1.
Compressing the log in this way leads to the following algorithm, the state-based counter CRDT.
- Per-user state: A
Map<ReplicaID, number>, mapping eachreplicaIDto the number of+1operations received from that replica. (Traditionally, this state is called a vector instead of a map.) - App-visible state (the count): Sum of the map values.
- Operation
+1: Add 1 to your own map entry, treating a missing entry as 0. - Merge in other state: Take the entry-wise max of values, treating missing entries as 0. That is, for all
r, setthis.state[r] = max(this.state[r] ?? 0, other.state[r] ?? 0).
For example:
// Starting local state:
{
a6X7fx: 2, // Implies ops ((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1")
bu91nD: 3,
}
// Other state:
{
a6X7fx: 4, // Implies ops ((a6X7fx, 1), "+1"), ..., ((a6X7fx, 4), "+1")
bu91nD: 1,
yyn898: 2
}
// Merged result:
{
a6X7fx: 4, // Implies ops ((a6X7fx, 1), "+1"), ..., ((a6X7fx, 4), "+1"): union of inputs
bu91nD: 3,
yyn898: 2
}
You can generalize the state-based counter to handle +x operations for arbitrary positive values x. However, to handle both positive and negative additions, you need to use two counters: P for positive additions and N for negative additions. The actual value is (P's value) - (N's value). This is the state-based PN-counter.
Collabs: CCounter
Refs: Shapiro et al. 2011a
Delta-State Based Counter
You can modify the state-based counter CRDT to also support op-based messages:
- When a user performs a
+1operation, broadcast its dot ID(r, c). - Recipients add this dot their compresed log
map, by settingmap[r] = max(map[r], c).
This hybrid op-based/state-based CRDT is called the delta-state based counter CRDT.
Technically, the delta-state based counter CRDT assumes causal-order delivery for op-based messages. Without this assumption, a replica’s uncompressed log might contain gaps like
[
((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1"), ((a6X7fx, 3), "+1"), ((a6X7fx, 6), "+1")
]
which we can’t represent as a Map<ReplicaID, number>.
You could argue that the operation
((a6X7fx, 6), "+1")lets you “infer” the prior operations((a6X7fx, 4), "+1")and((a6X7fx, 5), "+1"), hence you can just set the map entry to{ a6X7fx: 6 }. However, this will give an unexpected counter value if those prior operations were deliberately undone, or if they’re tied to some other change that can’t be inferred (e.g., a count of comments vs the actual list of comments).
Luckily, you can still compress ranges within the dot IDs that you have received. For example, you could use a run-length encoding:
{
a6X7fx: [1 through 3, 6 through 6]
}
or a map plus a set of “extra” dot IDs:
{
map: {
a6X7fx: 3
},
dots: [["a6X7fx", 6]]
}
This idea leads to a second delta-state based counter CRDT. Its state-based merge algorithm is somewhat complicated, but it has a simple spec: decompress both inputs, take the union, and re-compress.
Refs: Almeida, Shoker, and Baquero 2016
State-Based Unique Set
Here is a straightforward state-based CRDT for the unique set:
- Per-user state:
- A set of elements
(id, x), which is the set’s literal (app-visible) state. - A set of tombstones
id, which are the UIDs of all deleted elements.
- A set of elements
- App-visible state: Return
elements. - Operation
add(x): Generate a new UIDid, then add(id, x)toelements. - Operation
delete(id): Delete the pair with the givenidfromelements, and addidtotombstones. - State-based merge: To merge in another user’s state
other = { elements, tombstones },- For each
(id, x)inother.elements, if it is not already present inthis.elementsandidis not inthis.tombstones, add(id, x)tothis.elements. - For each
idinother.tombstones, if it is not already present inthis.tombstones, addidtothis.tombstonesand delete the pair with the givenidfromthis.elements(if present).
- For each
For example:
// Starting local state:
{
elements: [ (("A84nxi", 1), "milk"), (("A84nxi", 3), "eggs") ],
tombstones: [ ("A84nxi", 2), ("bu2nVP", 1), ("bu2nVP", 2) ]
}
// Other state:
{
elements: [
(("A84nxi", 3), "eggs"), (("bu2nVP", 1), "bread"), (("bu2nVP", 2), "butter"),
(("bu2nVP", 3), "cereal")
],
tombstones: [ ("A84nxi", 1), ("A84nxi", 2) ]
}
// Merged result:
{
elements: [ (("A84nxi", 3), "eggs"), (("bu2nVP", 3), "cereal") ],
tombstones: [ ("A84nxi", 1), ("A84nxi", 2), ("bu2nVP", 1), ("bu2nVP", 2) ]
}
The problem with this straightforward algorithm is the tombstone set: it stores a UID for every deleted element, potentially making the CRDT state much larger than the app-visible state.
Luckily, when your UIDs are dot IDs, you can use a “compression” trick similar to the state-based counter CRDT: in place of the tombstone set, store the range of dot IDs received from each replica (deleted or not), as a Map<ReplicaID, number>. That is, store a modified vector clock that only counts add operations. Any dot ID that lies within this range, but is not present in elements, must have been deleted.
For example, the three states above compress to:
// Starting local state:
{
elements: [ (("A84nxi", 1), "milk"), (("A84nxi", 3), "eggs") ],
vc: { A84nxi: 3, bu2nVP: 2 }
}
// Other state:
{
elements: [
(("A84nxi", 3), "eggs"), (("bu2nVP", 1), "bread"), (("bu2nVP", 2), "butter"),
(("bu2nVP", 3), "cereal")
],
vc: { A84nxi: 3, bu2nVP: 3 }
}
// Merged result:
{
elements: [ (("A84nxi", 3), "eggs"), (("bu2nVP", 3), "cereal") ],
vc: { A84nxi: 3, bu2nVP: 3 }
}
Compressing the tombstone set in this way leads to the following algorithm, the optimized state-based unique set:
- Per-user state:
- A set of elements
(id, x) = ((r, c), x). - A vector clock
vc: Map<ReplicaID, number>. - A local counter
counter, used for dot IDs.
- A set of elements
- App-visible state: Return
elements. - Operation
add(x): Generate a new dotid = (local replicaID, ++counter), then add(id, x)toelements. Also incrementvc[local replicaID]. - Operation
delete(id): Merely delete the pair with the givenidfromelements. - State-based merge: To merge in another user’s state
other = { elements, vc },- For each
((r, c), x)inother.elements, if it is not already present inthis.elementsandc > this.vc[r], add((r, c), x)tothis.elements. (It’s new and has not been deleted locally.) - For each entry
(r, c)inother.vc, for each pair((r, c'), x)inthis.elements, ifc >= c'and the pair is not present inother.elements, delete it fromthis.elements. (It must have been deleted from the other state.) - Set
this.vcto the entry-wise max ofthis.vcandother.vc, treating missing entries as 0. That is, for allr, setthis.vc[r] = max(this.vc[r] ?? 0, other.vc[r] ?? 0).
- For each
You can re-use the same vector clock that you use for tracking operations, if your unique set’s dot IDs use the same counter. Nitpicks:
- Your unique set might skip over some dot IDs, because they are used for other operations; that is fine.
- If a single operation can add multiple elements at once, consider using UIDs of the form
(dot ID, within-op counter) = (replicaID, per-op counter, within-op counter).
The optimized unique set is especially important because you can implement many other CRDTs on top, which are then also optimized (they avoid tombstones). In particular, Part 2 describes unique set algorithms for the multi-value register, multi-value map, and add-wins set (all assuming causal-order delivery). You can also adapt the optimized unique set to manage deletions in the unique set of CRDTs.
Collabs: CMultiValueMap, CSet
Refs: Based on the Optimized OR-Set from Bieniusa et al. 2012
Delta-State Based Unique Set
Similar to the second delta-state based counter CRDT, you can create a delta-state based unique set that is a hybrid op-based/state-based CRDT and allows non-causal-order message delivery. I’ll leave it as an exercise.
Refs: Causal δ-CRDTs in Almeida, Shoker, and Baquero 2016
Conclusion
The last two posts surveyed the two “topics” from Part 1:
- Semantics: An abstract description of what a collaborative app’s state should be, given its concurrency-aware operation history.
- Algorithms: Algorithms to efficiently compute the app’s state in specific, practical situations.
Together, they covered much of the CRDT theory that I know and use. I hope that you now know it too!
However, there are additional CRDT ideas outside my focus area. I’ll give a bibliography for those in the next and final post, Part 4: Further Topics.
This blog post is Part 3 of a series.
Home • Matthew Weidner • Common Curriculum / CMU PhD student • mweidner037 [at] gmail.com • @MatthewWeidner3 • @mweidner.bsky.social • LinkedIn • GitHub