CRDT Survey, Part 2: Semantic Techniques
Matthew Weidner |
Oct 17th, 2023
Home | RSS Feed
Keywords: CRDTs, collaborative apps, semantics
This blog post is Part 2 of a series.
Semantic Techniques
In Part 1, I defined a collaborative app’s semantics as an abstract definition of what the app’s state should be, given the operations that users have performed.
Your choice of semantics should be informed by users’ intents and expectations: if one user does X while an offline user concurrently does Y, what do the users want to happen when they sync up? Even after you figure out specific scenarios, though, it is tricky to design a strategy that is well-defined in every situation (multi-way concurrency, extensive offline work, etc.).
CRDT semantic techniques help you with this goal. Like the data structures and design patterns that you learn about when programming single-user apps, these techniques provide valuable guidance, but they are not a replacement for deciding what your app should actually do.
The techniques come in various forms:
- Specific building blocks - e.g., list CRDT positions. (Single-user app analogy: specific data structures like a hash map.)
- General-purpose ideas that must be applied wisely - e.g., unique IDs. (Single-user analogy: object-oriented programming techniques.)
- Example semantics for specific parts of a collaborative app - e.g., a list with a move operation. (Single-user analogy: Learning from an existing app’s architecture.)
Some of these techniques will be familiar if you’ve read Designing Data Structures for Collaborative Apps, but I promise there are new ones here as well.
Table of Contents
This post is meant to be usable as a reference. However, some techniques build on prior techniques. I recommend reading linearly until you reach Composed Examples, then hopping around to whatever interests you.
Describing Semantics
I’ll describe a CRDT’s semantics by specifying a pure function of the operation history: a function that inputs the history of operations that users have performed, and outputs the current app-visible state.
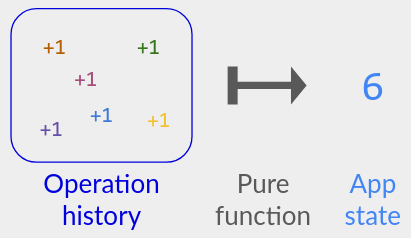
Note that I don’t expect you to implement a literal “operation history + pure function”; that would be inefficient. Instead, you are supposed to implement an algorithm that gives the same result. E.g., an op-based CRDT that satisfies: whenever a user has received the messages corresponding to operations S, the user’s state matches the pure function applied to S. I’ll give a few of these algorithms below, and more in Part 3.
More precisely, I’ll describe a CRDT’s semantics as:
- A collection of operations that users are allowed to perform on the CRDT. Example: Call
inc()to increment a counter. - For each operation, a translated version that gets stored in the (abstract) operation history. Example: When a user deletes the ingredient at index 0 in an ingredients list, we might instead store the operation
Delete the ingredient with unique ID <xyz>. - A pure function that inputs a set of translated operations and some ordering metadata (next paragraph), and outputs the intended state of a user who is aware of those operations. Example: A counter’s semantic function inputs the set of
inc()operations and outputs its size, ignoring ordering metadata.
The “ordering metadata” is a collection of arrows indicating which operations were aware of each other. E.g., here is a diagram representing the operation history from Part 1:
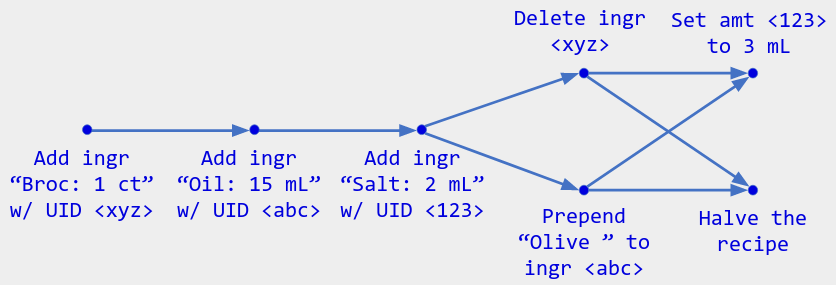
- One user performs a sequence of operations to create the initial recipe.
- After seeing those operations, two users concurrently do
Delete ingredient <xyz>andPrepend "Olive " to ingredient <abc>. - After seeing each other’s operations, the two users do two more concurrent operations.
I’ll use diagrams like this throughout the post to represent operation histories. You can think of them like git commit graphs, except that each point is labeled with its operation instead of its state/hash, and parallel “heads” (the rightmost points) are implicitly merged.
Example: A user who has received the above operation history already sees the result of both heads Set amt <123> to 3 mL and <Halve the recipe>, even though there is no “merge commit”. If that user performs another operation, it will get arrows from both heads, like an explicit merge commit:
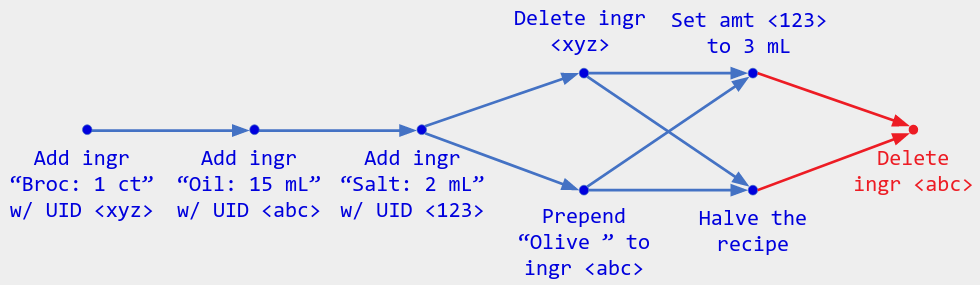
Describing semantics in terms of a pure function of the operation history lets us sidestep the usual CRDT rules like “concurrent messages must commute” and “the merge function must be idempotent”. Indeed, the point of those rules is to guarantee that a given CRDT algorithm corresponds to some pure function of the operation history (cf. Part 1’s definition of a CRDT). We instead directly say what pure function we want, then define CRDTs to match (or trust you to do so).
Strong convergence is the property that a CRDT’s state is a pure function of the operation history - i.e., users who have received the same set of ops are in equivalent states. Strong Eventual Consistency (SEC) additionally requires that two users who stop performing operations will eventually be in equivalent states; it follows from strong convergence in any network where users eventually exchange operations (Shapiro et al. 2011b).
These properties are necessary for collaborative apps, but they are not sufficient: you still need to check that your CRDT’s specific semantics are reasonable for your app. It is easy to forget this if you get bogged down in e.g. a proof that concurrent messages commute.
Causal Order
Formally, arrows in our operation history diagrams indicate the “causal order” on operations. We will use the causal order to define the multi-value register and some later techniques, so if you want a formal definition, read this section first (else you can skip ahead).
The causal order is the partial order < on pairs of operations defined by:
- If a user had received operation
obefore performing their own operationp, theno < p. This includes the case that they performed bothoandpin that order. - (Transitivity) If
o < pandp < q, theno < q.
Our operation histories indicate o < p by drawing an arrow from o to p. Except, we omit arrows that are implied by transitivity - equivalently, by following a sequence of other arrows.
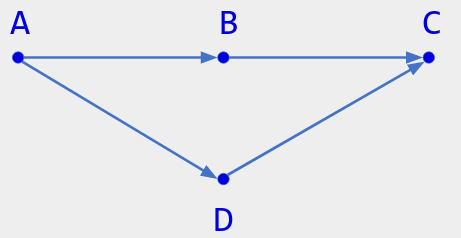
Figure 1. One user performs operations A, B, C in sequence. After receiving A but not B, another user performs D; the first user receives that before performing D. The causal order is then A < B, A < C, A < D, B < C, D < C. In the figure, the arrow for A < C is implied.
Some derived terms:
- When
o < p, we say thatois causally prior top/ois a causal predecessor ofp, andpis causally greater thano. - When we neither have
o < pnorp < o, we say thatoandpare concurrent. - When
o < p, you may also see the phrases “ohappened-beforep” or “pis causally aware ofo”. ois an immediate causal predecessor ofpifo < pand there is norsuch thato < r < p. These are precisely the pairs(o, p)connected by an arrow in our operation histories: all non-immediate causal predecessors are implied by transitivity.
In the above figure, B is causally greater than A, causally prior to C, and concurrent to D. The immediate causal predecessors of C are B and D; A is a causal predecessor, but not an immediate one.
It is easy to track the causal order in a CRDT setting: label each operation by IDs for its immediate causal predecessors (the tails of its incoming arrows). Thus when choosing our “pure function of the operation history”, it is okay if that function queries the causal order. We will see an example of this in the multi-value register.
Often, CRDT-based apps choose to enforce causal-order delivery: a user’s app will not process an operation (updating the app’s state) until after processing all causally-prior operations. (An op may be processed in any order relative to concurrent operations.) In other words, operations are processed in causal order. This simplifies programming and makes sense to users, by providing a guarantee called causal consistency. For example, it ensures that if one user adds an ingredient to a recipe and then writes instructions for it, all users will see the ingredient before the instructions. However, there are times when you might choose to forgo causal-order delivery - e.g., when there are undone operations. (More examples in Part 4).
In Collabs: CRuntime (causal-order delivery), vectorClock (causal order access)
References: Lamport 1978
Basic Techniques
We begin with basic semantic techniques. Most of these were not invented as CRDTs; instead, they are database techniques or programming folklore. It is often easy to implement them yourself or use them outside of a traditional CRDT framework.
Unique IDs (UIDs)
To refer to a piece of content, assign it an immutable Unique ID (UID). Use that UID in operations involving the content, instead of using a mutable descriptor like its index in a list.
Example: In a recipe editor, assign each ingredient a UID. When a user edits an ingredient’s amount, indicate which ingredient using its UID. This solves Part 1’s example.
By “piece of content”, I mean anything that the user views as a distinct “thing”, with its own long-lived identity: an ingredient, a spreadsheet cell, a document, etc. Note that the content may be internally mutable. Other analogies:
- Anything that would be its own object in a single-user app. Its UID is the distributed version of a “pointer” to that object.
- Anything that would get its own row in a normalized database table. Its UID functions as the primary key.
To ensure that all users agree on a piece of content’s UID, the content’s creator should assign the UID at creation time and broadcast it. E.g., include a new ingredient’s UID in the corresponding “Add Ingredient” operation. The assigned UID must be unique even if multiple users create UIDs concurrently; you can ensure that by using UUIDs, or Part 3’s dot IDs.
UIDs are useful even in non-collaborative contexts. For example, a single-user spreadsheet formula that references cell B3 should store the UIDs of its column (B) and row (3) instead of the literal string “B3”. That way, the formula still references “the same cell” even if a new row shifts the cell to B4.
Append-Only Log
Use an append-only log to record events indefinitely. This is a CRDT with a single operation add(x), where x is an immutable value to store alongside the event. Internally, add(x) gets translated to an operation add(id, x), where id is a new UID; this lets you distinguish events with the same values. Given an operation history made of these add(id, x) events, the current state is just the set of all pairs (id, x).
Example: In a delivery tracking system, each package’s history is an append-only log of events. Each event’s value describes what happened (scanned, delivered, etc.) and the wall-clock time. The app displays the events directly to the user in wall-clock time order. Conflicting concurrent operations indicate a real-world conflict and must be resolved manually.
I usually think of an append-only log as unordered, like a set (despite the word “append”). If you do want to display events in a consistent order, you can include a timestamp in the value and sort by that, or use a list CRDT (below) instead of an append-only log. Consider using a logical timestamp like in LWW, so that the order is compatible with the causal order: o < p implies o appears before p.
Refs: Log in Shapiro et al. 2011b
Unique Set
A unique set is like an append-only log, but it also allows deletes. It is the basis for any collection that grows and shrinks dynamically: sets, lists, certain maps, etc.
Its operations are:
add(x): Adds an operationadd(id, x)to the history, whereidis a new UID. (This is the same as the append-only log’sadd(x), except that we call the entry an element instead of an event.)delete(id), whereidis the UID of the element to be deleted.
Given an operation history, the unique set’s state is the set of pairs (id, x) such that there is an add(id, x) operation but no delete(id) operations.
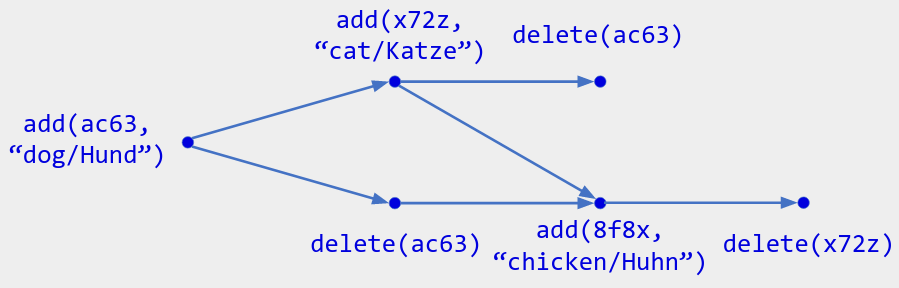
Figure 2. In a collaborative flash card app, you could represent the deck of cards as a unique set, using x to hold the flash card's value (its front and back strings). Users can edit the deck by adding a new card or deleting an existing one, and duplicate cards are allowed. Given the above operation history, the current state is { (8f8x, "chicken/Huhn") }.
You can think of the unique set as an obvious way of working with UID-labeled content. It is analogous to a database table with operations to insert and delete rows, using the UID (= primary key) to identify rows. Or, thinking of UIDs like distributed pointers, add and delete are the distributed versions of new and free.
It’s easy to convert the unique set’s semantics to an op-based CRDT.
- Per-user state: The literal state, which is a set of pairs
(id, x).- Operation
add(x): Generate a new UIDid, then broadcastadd(id, x). Upon receiving this message, each user (including the initiator) adds the pair(id, x)to their local state.- Operation
delete(id): Broadcastdelete(id). Upon receiving this message, each user deletes the pair with the givenid, if it is still present. Note: this assumes causal-order delivery - otherwise, you might receivedelete(id)beforeadd(id, x), then forget that the element is deleted.A state-based CRDT is more difficult; Part 3 will give a nontrivial optimized algorithm.
Refs: U-Set in Shapiro et al. 2011a
Lists and Text Editing
In collaborative text editing, users can insert (type) and delete characters in an ordered list. Inserting or deleting a character shifts later characters’ indices, in the style of JavaScript’s Array.splice.
The CRDT way to handle this is: assign each character a unique immutable list CRDT position when it’s typed. These positions are a special kind of UID that are ordered: given two positions p and q, you can ask whether p < q or q < p. Then the text’s state is given by:
- Sort all list elements
(position, char)byposition. - Display the characters in that order.
Classic list CRDTs have operations insert and delete, which are like the unique set’s add and delete operations, except using positions instead of generic UIDs. A text CRDT is the same but with individual text characters for values. See a previous blog post for details.
But the real semantic technique is the positions themselves. Abstractly, they are “opaque things that are immutable and ordered”. To match users’ expectations, list CRDT positions must satisfy a few rules (Attiya et al. 2016):
- The order is total: if
pandqare distinct positions, then eitherp < qorq < p, even ifpandqwere created by different users concurrently. - If
p < qon one user’s device at one time, thenp < qon all users’ devices at all times. Example: characters in a collaborative text document do not reverse order, no matter what happens to characters around them. - If
p < qandq < r, thenp < r. This holds even ifqis not currently part of the app’s state.
This definition still gives us some freedom in choosing <. The Fugue paper (myself and Martin Kleppmann, 2023) gives a particular choice of < and motivates why we think you should prefer it over any other. Seph Gentle’s Diamond Types and the Braid group’s Sync9 each independently chose nearly identical semantics (thanks to Michael Toomim and Greg Little for bringing the latter to our attention).
List CRDT positions are our first “real” CRDT technique - they don’t come from databases or programming folklore, and it is not obvious how to implement them. Their algorithms have a reputation for difficulty, but you usually only need to understand the “unique immutable position” abstraction, which is simple. You can even use list CRDT positions outside of a traditional CRDT framework, e.g., using my list-positions library.
Collabs: CValueList, Position.
Refs: Many - see “Background and Related Work” in the Fugue paper
Last Writer Wins (LWW)
If multiple users set a value concurrently, and there is no better way to resolve this conflict, just pick the “last” value as the winner. This is the Last Writer Wins (LWW) rule.
Example: Two users concurrently change the color of a pixel in a shared whiteboard. Use LWW to pick the final color.
Traditionally, “last” meant “the last value to reach the central database”. In a CRDT setting, instead, when a user performs an operation, their own device assigns a timestamp for that operation. The operation with the greatest assigned timestamp wins: its value is the one displayed to the user.
Formally, an LWW register is a CRDT representing a single variable, with sole operation set(value, timestamp). Given an operation history made of these set operations, the current state is the value with the largest timestamp.
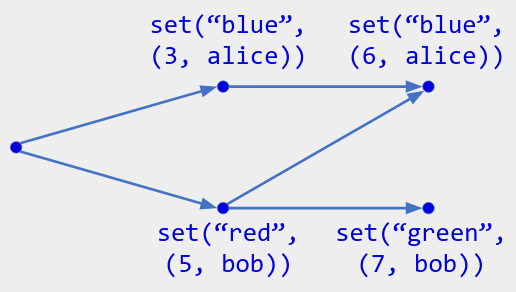
Figure 3. Possible operation history for an LWW register using logical timestamps (the pairs (3, "alice")). The greatest assigned timestamp is (7, bob), so the current state is "green".
The timestamp should usually be a logical timestamp instead of literal wall-clock time (e.g., a Lamport timestamp. Otherwise, clock skew can cause a confusing situation: you try to overwrite the current local value with a new one, but your clock is behind, so the current value remains the winner. Lamport timestamps also build in a tiebreaker so that the winner is never ambiguous.
Let’s make these semantics concrete by converting them to a hybrid op-based/state-based CRDT. Specifically, we’ll do an LWW register with value type
T.
- Per-user state:
state = { value: T, time: LogicalTimestamp }.- Operation
set(newValue): Broadcast an op-based CRDT message{ newValue, newTime }, wherenewTimeis the current logical time. Upon receiving this message, each user (including the initiator) does:
- If
newTime > state.time, setstate = { value: newValue, time: newTime }.- State-based merge: To merge in another user’s state
other = { value, time }, treat it like an op-based message: ifother.time > state.time, setstate = other.You can check that
state.valuealways comes from the received operation with the greatest assigned timestamp, matching our semantics above.
When using LWW, pay attention to the granularity of writes. For example, in a slide editor, suppose one user moves an image while another user resizes it concurrently. If you implement both actions as writes to a single LWWRegister<{ x, y, width, height }>, then one action will overwrite the other - probably not what you want. Instead, use two different LWW registers, one for { x, y } and one for { width, height }, so that both actions can take effect.
Collabs: lamportTimestamp
Refs: Johnson and Thomas 1976; Shapiro et al. 2011a
LWW Map
An LWW map applies the last-writer-wins rule to each value in a map. Formally, its operations are set(key, value, timestamp) and delete(key, timestamp). The current state is given by:
- For each
key, find the operation onkeywith the largest timestamp. - If the operation is
set(key, value, timestamp), then the value atkeyisvalue. - Otherwise (i.e., the operation is
delete(key, timestamp)or there are no operations onkey),keyis not present in the map.
Observe that a delete operation behaves just like a set operation with a special value. In particular, when implementing the LWW map, it is not safe to forget about deleted keys: you have to remember their latest timestamps as usual, for future LWW comparisons. Otherwise, your semantics might be ill-defined (not a pure function of the operation history), as pointed out by Kleppmann (2022).
In the next section, we’ll see an alternative semantics that does let you forget about deleted keys: the multi-value map.
Multi-Value Register
This is another “real” CRDT technique, and our first technique that explicitly references the arrows in an operation history (formally, the causal order).
When multiple users set a value concurrently, sometimes you want to preserve all of the conflicting values, instead of just applying LWW.
Example: One user enters a complex, powerful formula in a spreadsheet cell. Concurrently, another user figures out the intended value by hand and enters that. The first user will be annoyed if the second user’s write erases their hard work.
The multi-value register does this, by following the rule: its current value is the set of all values that have not yet been overwritten. Specifically, it has a single operation set(x). Its current state is the set of all values whose operations are at the heads of the operation history (formally, the maximal operations in the causal order). For example, here the current state is { "gray", "blue" }:
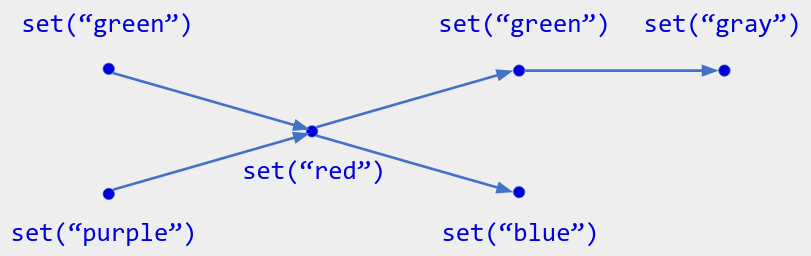
Multi-values (also called conflicts) are hard to display, so you should have a single value that you show by default. This displayed value can be chosen arbitrarily (e.g. LWW), or by some semantic rule. For example:
- In a bug tracking system, if a bug has multiple conflicting priorities, display the highest one (Zawirski et al. 2016).
- For a boolean value, if any of the multi-values are true, display true. This yields the enable-wins flag CRDT. Alternatively, if any of the multi-values are false, display false (a disable-wins flag).
Other multi-values can be shown on demand, like in Pixelpusher, or just hidden.
As with LWW, pay attention to the granularity of writes.
The multi-value register sounds hard to implement because it references the causal order. But actually, if your app enforces causal-order delivery, then you can easily implement a multi-value register on top of a unique set.
- Per-user state: A unique set
uSetof pairs(id, x). The multi-values are all of thex’s.- Operation
set(x): Locally, loop overuSetcallinguSet.delete(id)on every existing element. Then calluSet.add(x).Convince yourself that this gives the same semantics as above.
Collabs: CVar
Refs: Shapiro et al. 2011a; Zawirski et al. 2016
Multi-Value Map
Like the LWW map, a multi-value map applies the multi-value register semantics to each value in a map. Formally, its operations are set(key, value) and delete(key). The current state is given by:
- For each
key, consider the operation history restricted toset(key, value)anddelete(key)operations. - Among those operations, restrict to the heads of the operation history. Equivalently, these are the operations that have not been overwritten by another
keyoperation. Formally, they are the maximal operations in the causal order. - The value at
keyis the set of all values appearing among the heads’setoperations. If this set is empty, thenkeyis not present in the map.
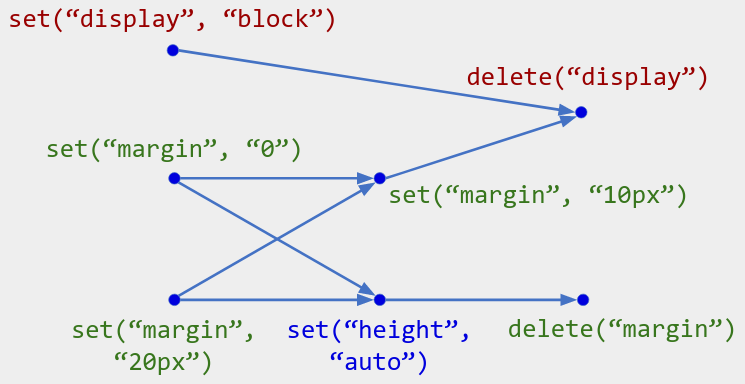
Figure 4. Multi-value map operations on a CSS class. Obviously key "height" maps to the single value "auto", while key "display" is not present in the map. For key "margin", observe that when restricting to its operations, only set("margin", "10px") and delete("margin") are heads of the operation history (i.e., not overwritten); thus "margin" maps to the single value "10px".
As with the multi-value register, each present key can have a displayed value that you show by default. For example, you could apply LWW to the multi-values. That gives a semantics similar to the LWW map, but when you implement it as an op-based CRDT, you can forget about deleted values. (Hint: Implement the multi-value map on top of a unique set like above.)
Collabs: CValueMap
Refs: Kleppmann 2022
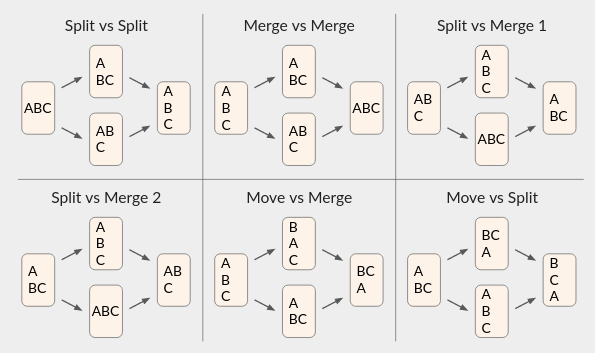
Composition Techniques
We next move on to composition techniques. These create new CRDTs from existing ones.
Composition has several benefits over making a CRDT from scratch:
- Semantically, you are guaranteed that the composed output is actually a CRDT: its state is always a pure function of the operation history (i.e., users who have received the same set of ops are in equivalent states).
- Algorithmically, you get op-based and state-based CRDT algorithms “for free” from the components. Those components are probably already optimized and tested.
- It is much easier to add a new system feature (e.g., undo/redo) to a few basic CRDTs and composition techniques, than to add it to your app’s top-level state directly.
In particular, it is safe to use a composed algorithm that appears to work well in the situations you care about (e.g., all pairs of concurrent operations), even if you are not sure what it will do in arbitrarily complex scenarios. You are guaranteed that it will at least satisfy strong convergence and have equivalent op-based vs state-based behaviors.
Like most of our basic techniques, these composition techniques are not really CRDT-specific, and you can easily use them outside of a traditional CRDT framework. Figma’s collaboration system is a good example of this.
Views
Not all app states have a good CRDT representation. But often you can store some underlying state as a CRDT, then compute your app’s state as a view (pure function) of that CRDT state.
Example: Suppose a collaborative text editor represents its state as a linked list of characters. Storing the linked list directly as a CRDT would cause trouble: concurrent operations can easily cause broken links, partitions, and cycles. Instead, store a traditional list CRDT, then construct the linked list representation as a view of that at runtime.
At runtime, one way to obtain the view is to apply a pure function to your CRDT state each time that CRDT state changes, or each time the view is requested. This should sound familiar to web developers (React, Elm, …).
Another way is to “maintain” the view, updating it incrementally each time the CRDT state changes. CRDT libraries usually emit “events” that make this possible. View maintenance is a known hard problem, but it is not hard in a CRDT-specific way. Also, it is easy to unit test: you can always compare to the pure-function approach.
Collabs: Events
Objects
It is natural to wrap a CRDT in an app-specific API: when the user performs an operation in the app, call a corresponding CRDT operation; in the GUI, render an app-specific view of the CRDT’s state.
More generally, you can create a new CRDT by wrapping multiple CRDTs in a single API. I call this object composition. The individual CRDTs (the components) are just used side-by-side; they don’t affect each others’ operations or states.
Example: An ingredient like we saw in Part 1 (reproduced below) can be modeled as the object composition of three CRDTs: a text CRDT for the text, an LWW register for the amount, and another LWW register for the units.

To distinguish the component CRDTs’ operations, assign each component a distinct name. Then tag each component’s operations with its name:
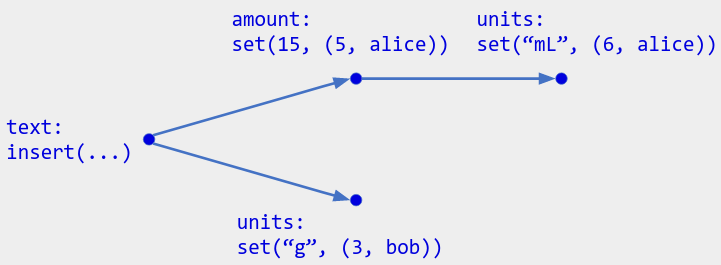
One way to think of the composed CRDT is as a literal CRDT object - a class whose instance fields are the component CRDTs:
class IngredientCRDT extends CRDTObject {
text: TextCRDT;
amount: LWWRegister<number>;
units: LWWRegister<Unit>;
setAmount(newAmount: number) {
this.amount.set(newAmount);
}
...
}
Another way to think of the composed state is as a JSON object mapping names to component states:
{
text: {<text CRDT state...>},
amount: { value: number, time: LogicalTimestamp },
units: { value: Unit, time: LogicalTimestamp }
}
Collabs: CObject
Refs: See Map-Like Object refs below
Nested Objects
You can nest objects arbitrarily. This leads to layered object-oriented architectures:
class SlideImageCRDT extends CRDTObject {
dimensions: DimensionCRDT;
contents: ImageContentsCRDT;
}
class DimensionCRDT extends CRDTObject {
position: LWWRegister<{ x: number, y: number }>;
size: LWWRegister<{ width: number, height: number }>;
}
class ImageContentsCRDT ...
or to JSON-like trees:
{
dimensions: {
height: { value: number, time: LogicalTimestamp },
width: { value: number, time: LogicalTimestamp }
},
contents: {
...
}
}
Either way, tag each operation with the tree-path leading to its leaf CRDT. For example, to set the width to 75 pixels: { path: "dimensions/width", op: "set('75px', (11, alice))" }.
Map-Like Object
Instead of a fixed number of component CRDTs with fixed names, you can allow names drawn from some large set (possibly infinite). This gives you a form of CRDT-valued map, which I will call a map-like object. Each map key functions as the name for its own value CRDT.
Example: A geography app lets users add a description to any address on earth. You can model this as a map from address to text CRDT. The map behaves the same as an object that has a text CRDT instance field per address.
The difference from a CRDT object is that in a map-like object, you don’t store every value CRDT explicitly. Instead, each value CRDT exists implicitly, in some default state, until used. In the JSON representation, this leads to behavior like Firebase RTDB, where
{ foo: {/* Empty text CRDT */}, bar: {<text CRDT state...>} }
is indistinguishable from
{ bar: {<text CRDT state...>} }
Note that unlike an ordinary map, a map-like object does not have operations to set/delete a key; each key implicitly always exists, with a pre-set value CRDT. We’ll see a more traditional map with set/delete operations later.
The map-like object and similar CRDTs are often referred to as “map CRDTs” or “CRDT-valued maps” (I’ve done so myself). To avoid confusion, in this blog series, I will reserve those terms for maps with set/delete operations.
Collabs: CLazyMap
Refs: Riak Map; Conway et al. 2012; Kuper and Newton 2013
Unique Set of CRDTs
Another composition technique uses UIDs as the names of value CRDTs. This gives the unique set of CRDTs.
Its operations are:
add(initialState): Adds an operationadd(id, initialState)to the history, whereidis a new UID. This creates a new value CRDT with the given initial state.- Value CRDT operations: Any user can perform operations on any value CRDT, tagged with the value’s UID. The UID has the same function as object composition’s component names.
delete(id), whereidis the UID of the value CRDT to be deleted.
Given an operation history, the unique set of CRDT’s current state consists of all added value CRDTs, minus the deleted ones, in their own current states (according to the value CRDT operations). Formally:
for each add(id, initialState) operation:
if there are no delete(id) operations:
valueOps = all value CRDT operations tagged with id
currentState = result of value CRDT's semantics applied to valueOps and initialState
Add (id, currentState) to the set's current state
Example: In a collaborative flash card app, you could represent the deck of cards as a unique set of “flash card CRDTs”. Each flash card CRDT is an object containing text CRDTs for the front and back text. Users can edit the deck by adding a new card (with initial text), deleting an existing card, or editing a card’s front/back text. This extends our earlier flash card example.
Observe that once a value CRDT is deleted, it is deleted permanently. Even if another user operates on the value CRDT concurrently, it remains deleted. That allows an implementation to reclaim memory after receiving a delete op - it only needs to store the states of currently-present values. But it is not always the best semantics, so we’ll discuss alternatives below.
Like the unique set of (immutable) values, you can think of the unique set of CRDTs as an obvious way of working with UIDs in a JSON tree. Indeed, Firebase RTDB’s push method works just like add.
// JSON representation of the flash card example:
{
"uid838x": {
front: {<text CRDT state...>},
back: {<text CRDT state...>}
},
"uid7b9J": {
front: {<text CRDT state...>},
back: {<text CRDT state...>}
},
...
}
The unique set of CRDTs also matches the semantics you would get from normalized database tables: UIDs in one table; value CRDT operations in another table with the UID as a foreign key. A delete op corresponds to a foreign key cascade-delete.
Firebase RTDB differs from the unique set of CRDTs in that its delete operations are not permanent - concurrent operations on a deleted value are not ignored, although the rest of the value remains deleted (leaving an awkward partial object). You can work around this behavior by tracking the set of not-yet-deleted UIDs separately from the actual values. When displaying the state, loop over the not-yet-deleted UIDs and display the corresponding values (only). Firebase already recommends this for performance reasons.
Collabs: CSet
Refs: Yjs’s Y.Array
List of CRDTs
By modifying the unique set of CRDTs to use list CRDT positions instead of UIDs, we get a list of CRDTs. Its value CRDTs are ordered.
Example: You can model the list of ingredients from Part 1 as a list of CRDTs, where each value CRDT is an ingredient object from above. Note that operations on a specific ingredient are tagged with its position (a kind of UID) instead of its index, as we anticipated in Part 1.
Collabs: CList
Refs: Yjs’s Y.Array
Composed Examples
We now turn to semantic techniques that can be described compositionally.
In principle, if your app needed one of these behaviors, you could figure it out yourself: think about the behavior you want, then make it using the above techniques. In practice, it’s good to see examples.
Add-Wins Set
The add-wins set represents a set of (non-unique) values. Its operations are add(x) and remove(x), where x is an immutable value of type T. Informally, its semantics are:
- Sequential
add(x)andremove(x)operations behave in the usual way for a set (e.g. Java’sHashSet). - If there are concurrent operations
add(x)andremove(x), then the add “wins”:xis in the set.
Example: A drawing app includes a palette of custom colors, which users can add or remove. You can model this as an add-wins set of colors.
The informal semantics do not actually cover all cases. Here is a formal description using composition:
- For each possible value
x, store a multi-value register indicating whetherxis currently in the set. Do so using a map-like object whose keys are the valuesx. In pseudocode:MapLikeObject<T, MultiValueRegister<boolean>>. add(x)translates to the operation “setx’s multi-value register to true”.remove(x)translates to the operation “setx’s multi-value register to false”.- If any of
x’s multi-values are true, thenxis in the set (enable-wins flag semantics). This is how we get the “add-wins” rule.
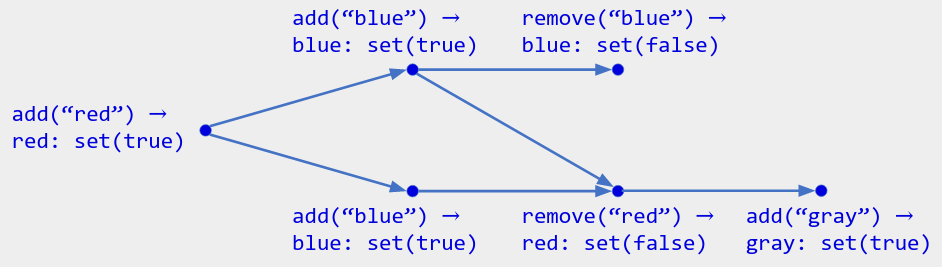
Figure 5. Operation history for a color palette's add-wins set of colors, showing (original op) -> (translated op). The current state is { "blue", "gray" }: the bottom add("blue") op wins over the concurrent remove("blue") op.
There is a second way to describe the add-wins set’s semantics using composition, though you must assume causal-order delivery:
- The state is a unique set of entries
(id, x). The current state is the set of valuesxappearing in at least one entry. add(x)translates to a unique-setadd(x)operation.remove(x)translates to: locally, loop over the entries(id, x); for each one, issuedelete(id)on the unique set.
The name observed-remove set - a synonym for add-wins set - reflects how this
remove(x)operation works: it deletes all entries(id, x)that the local user has “observed”.
Collabs: CValueSet
Refs: Shapiro et al. 2011a; Leijnse, Almeida, and Baquero 2019
List-with-Move
The lists above fix each element’s position when it is inserted. This is fine for text editing, but for other collaborative lists, you often want to move elements around. Moving an element shouldn’t interfere with concurrent operations on that element.
Example: In a collaborative recipe editor, users should be able to rearrange the order of ingredients using drag-and-drop. If one user edits an ingredient’s text while someone else moves it concurrently, those edits should show up on the moved ingredient, like the typo fix “Bredd” -> “Bread” here:
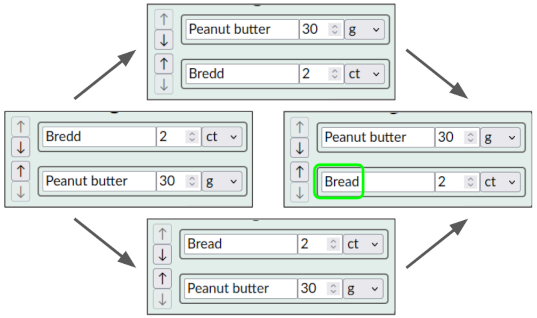
In the example, intuitively, each ingredient has its own identity. That identity is independent of the ingredient’s current position; instead, position is a mutable property of the ingredient.
Here is a general way to achieve those semantics, the list-with-move:
- Assign each list element a UID, independently of its position. (E.g., store the elements in a unique set of CRDTs, not a list of CRDTs.)
- To each element, add a
positionproperty, containing its current position in the list. - Move an element by setting its
positionto a new list CRDT position at the intended place. In case of concurrent move operations, apply LWW to their positions.
Sample pseudocode:
class IngredientCRDT extends CRDTObject {
position: LWWRegister<Position>; // List CRDT position
text: TextCRDT;
...
}
class IngredientListCRDT {
ingredients: UniqueSetOfCRDTs<IngredientCRDT>;
move(ingr: IngredientCRDT, newIndex: number) {
const newPos = /* new list CRDT position at newIndex */;
ingr.position.set(newPos);
}
}
Collabs: CList.move
Refs: Kleppmann 2020
Internally-Mutable Register
The registers above (LWW register, multi-value register) each represent a single immutable value. But sometimes, you want a value that is internally mutable, but can still be blind-set like a register - overriding concurrent mutations.
Example: A bulletin board has an “Employee of the Month” section that shows the employee’s name, photo, and a text box. Coworkers can edit the text box to give congratulations; it uses a text CRDT to allow simultaneous edits. Managers can change the current employee of the month, overwriting all three fields. If a manager changes the current employee while a coworker concurrently congratulates the previous employee, the latter’s edits should be ignored.
An internally-mutable register supports both set operations and internal mutations. Its state consists of:
uSet, a unique set of CRDTs, used to create value CRDTs.reg, a separate LWW or multi-value register whose value is a UID fromuSet.
The register’s visible state is the value CRDT indicated by reg. You internally mutate the value by performing operations on that value CRDT. To blind-set the value to initialState (overriding concurrent mutations), create a new value CRDT using uSet.add(initialState), then set reg to its UID.
Creating a new value CRDT is how we ensure that concurrent mutations are ignored: they apply to the old value CRDT, which is no longer shown. The old value CRDT can even be deleted from uSet to save memory.
The CRDT-valued map (next) is the same idea applied to each value in a map.
Collabs: CVar with CollabID values
Refs: true blind updates in Braun, Bieniusa, and Elberzhager (2021)
CRDT-Valued Map
The map-like object above does not have operations to set/delete a key - it is more like an object than a hash map.
Here is a CRDT-valued map that behaves more like a hash map. Its state consists of:
uSet, a unique set of CRDTs, used to create the value CRDTs.lwwMap, a separate last-writer-wins map whose values are UIDs fromuSet.
The map’s visible state is: key maps to the value CRDT with UID lwwMap[key]. (If key is not present in lwwMap, then it is also not present in the CRDT-valued map.)
Operations:
set(key, initialState)translates to{ uSet.add(initialState); lwwMap.set(key, (UID from previous op)); }. That is, the local user creates a new value CRDT, then setskeyto its UID.delete(key)translates tolwwMap.delete(key). Typically, implementations also calluSet.deleteon all existing value CRDTs forkey, since they are no longer reachable.
Note that if two users concurrently set a key, then one of their set ops will “win”, and the map will only show that user’s value CRDT. (The other value CRDT still exists in uSet.) This can be confusing if the two users meant to perform operations on “the same” value CRDT, merging their edits.
Example: A geography app lets users add a photo and description to any address on earth. Suppose you model the app as a CRDT-valued map from each address to a CRDT object { photo: LWWRegister<Image>, desc: TextCRDT }. If one user adds a photo to an unused address (necessarily calling map.set first), while another user adds a description concurrently (also calling map.set), then one CRDT object will overwrite the other:
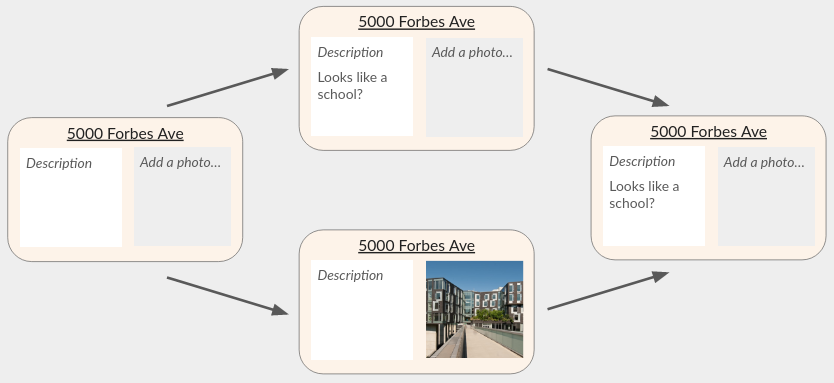
To avoid this, consider using a map-like object, like the previous geography app example.
More composed constructions that are similar to the CRDT-valued map:
- Same, except you don’t delete value CRDTs from
uSet. Instead, they are kept around in an archive. You can “restore” a value CRDT by callingset(key, id)again later, possibly under a differentkey.- A unique set of CRDTs where each value CRDT has a mutable
keyproperty, controlled by LWW. That way, you can change a value CRDT’s key - e.g., renaming a document. Note that your display must handle the case where multiple value CRDTs have the same key.
Refs: Yjs’s Y.Map; Automerge’s Map
Archiving Collections
The CRDT-valued collections above (unique set, list, map) all have a delete operation that permanently deletes a value CRDT. It is good to have this option for performance reasons, but you often instead want an archive operation, which merely hides an element until it’s restored. (You can recover most of delete’s performance benefits by swapping archived values to disk/cloud.)
Example: In a notes app with cross-device sync, the user should be able to view and restore deleted notes. That way, they cannot lose a note by accident.
To implement archive/restore, add an isPresent field to each value. Values start with isPresent = true. The operation archive(id) sets it to false, and restore(id) sets it to true. In case of concurrent archive/restore operations, you can apply LWW, or use a multi-value register’s displayed value.
Alternate implementation: Use a separate add-wins set to indicate which values are currently present.
Collabs: CList.archive/restore
Update-Wins Collections
If one user archives a value that another user is still using, you might choose to “auto-restore” that value.
Example: In a spreadsheet, one user deletes a column while another user edits some of that column’s cells concurrently. The second user probably wants to keep that column, and it’s easier if the column restores automatically (Yanakieva, Bird, and Bieniusa 2023).
To implement this on top of an archiving collection, merely call restore(id) each time the local user edits id’s CRDT. So each local operation translates to two ops in the history: the original (value CRDT) operation and restore(id).
To make sure that these “keep” operations win over concurrent archive operations, use an enable-wins flag to control the isPresent field. (I.e., a multi-value register whose displayed value is true if any of the multi-values are true.) Or, use the last section’s alternate implementation: an add-wins set of present values.
Collabs: supported by CList.restore
Refs: Yanakieva, Bird, and Bieniusa 2023
Spreadsheet Grid
In a spreadsheet, users can insert, delete, and potentially move rows and columns. That is, the collection of rows behaves like a list, as does the collection of columns. Thus the cell grid is the 2D analog of a list.
It’s tempting to model the grid as a list-of-lists. However, that has the wrong semantics in some scenarios. In particular, if one user creates a new row, while another user creates a new column concurrently, then there won’t be a cell at the intersection.
Instead, you should think of the state as:
- A list of rows.
- A list of columns.
- For each pair (row, column), a single cell, uniquely identified by the pair
(row id, column id).row idandcolumn idare unique IDs.
The cells are not explicitly created; instead, the state implicitly contains such a cell as soon as its row and column exist. Of course, until a cell is actually used, it remains in a default state (blank) and doesn’t need to be stored in memory. Once a user’s app learns that the row or column was deleted, it can forget the cell’s state, without an explicit “delete cell” operation - like a foreign key cascade-delete.
In terms of the composition techniques above (objects, list-with-move, map-like object):
class CellCRDT extends CRDTObject {
formula: LWWRegister<string>;
...
}
rows: ListWithMoveCRDT<Row>;
columns: ListWithMoveCRDT<Column>;
cells: MapLikeObject<(rowID: UID, columnID: UID), CellCRDT>;
// Note: if you use this compositional construction in an implementation,
// you must do extra work to forget deleted cells' states.
Advanced Techniques
The techniques in this section are more advanced. This really means that they come from more recent papers and I am less comfortable with them; they also have fewer existing implementations, if any.
Except for undo/redo, you can think of these as additional composed examples. However, they have more complex views than the previous composed examples.
Formatting Marks (Rich Text)
Rich text consists of plain text plus inline formatting: bold, font size, hyperlinks, etc. (This section does not consider block formatting like blockquotes or bulleted lists, discussed later.)
Inline formatting traditionally applies not to individual characters, but to spans of text: all characters from index i to j. E.g., atJSON (not a CRDT) uses the following to represent a bold span that affects characters 5 to 11:
{
type: "-offset-bold",
start: 5,
end: 11,
attributes: {}
}
Future characters inserted in the middle of the span should get the same format. Likewise for characters inserted at the end of the span, for certain formats. You can override (part of) the span by applying a new formatting span on top.
The inline formatting CRDT lets you use formatting spans in a CRDT setting. (I’m using this name for a specific part of the Peritext CRDT (Litt et al. 2021).) It consists of:
- An append-only log of CRDT-ified formatting spans, called marks.
- A view of the mark log that tells you the current formatting at each character.
Each mark has the following form:
{
key: string;
value: any;
timestamp: LogicalTimestamp;
start: { pos: Position, type: "before" | "after" }; // anchor
end: { pos: Position, type: "before" | "after" }; // anchor
}
Here timestamp is a logical timestamp for LWW, while each Position is a list CRDT position. This mark sets key to value (e.g. "bold": true) for all characters between start and end. The endpoints are anchors that exist just before or just after their pos:
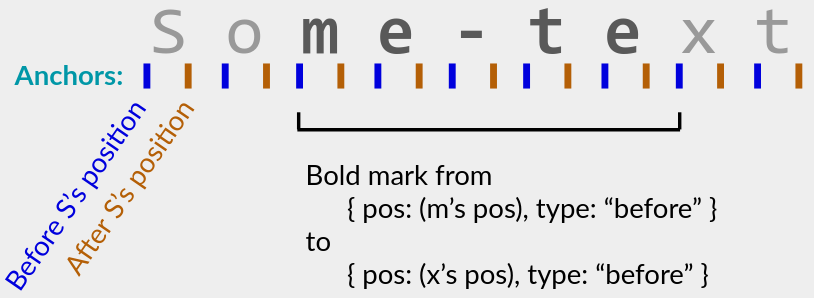
LWW takes effect when multiple marks affect the same character and have the same key: the one with the largest timestamp wins. In particular, new marks override (causally) older ones. Note that a new mark might override only part of an older mark’s range.
Formally, the view of the mark log is given by: for each character c, for each format key key, find the mark with the largest timestamp satisfying
mark.key = key, and- the interval
(mark.start, mark.end)containsc’s position.
Then c’s format value at key is mark.value.
Remarks:
- To unformat, apply a formatting mark with a
nullvalue, e.g.,{ key: "bold", value: null, ... }. This competes against other “bold” marks in LWW. - A formatting mark affects not just (causally) future characters in its range, but also characters inserted concurrently:

- Anchors let you choose whether a mark “expands” to affect future and concurrent characters at the beginning or end of its range. For example, the bold mark pictured above expands at the end: a character typed between
eandxwill still be within the mark’s range because the mark’s end is attached tox. - The view of the mark log is difficult to compute and store efficiently. Part 3 will describe an optimized view that can be maintained incrementally and doesn’t store metadata on every character.
- Sometimes a new character should be bold (etc.) according to local rules, but existing formatting marks don’t make it bold. E.g., a character inserted at the beginning of a paragraph in MSWord inherits the following character’s formatting, but the inline formatting CRDT doesn’t do that automatically.
To handle this, when a user types a new character, compute its formatting according to local rules. (Most rich-text editor libraries already do so.) If the inline formatting CRDT currently assigns different formatting to that character, fix it by adding new marks to the log.
Fancy extension to (5): Usually the local rules are “extending” a formatting mark in some direction - e.g., backwards from the paragraph’s previous starting character. You can figure out which mark is being extended, then reuse its
timestampinstead of making a new one. That way, LWW behaves identically for your new mark vs the one it’s extending.
Collabs: CRichText
Refs: Litt et al. 2021 (Peritext)
Spreadsheet Formatting
You can also apply inline formatting to non-text lists. For example, Google Sheets lets you bold a range of rows, with similar behavior to a range of bold text: new rows at the middle or end of the range are also bold. A cell in a bold row renders as bold, unless you override the formatting for that cell.
In more detail, here’s an idea for spreadsheet formatting:
Use two inline formatting CRDTs, one for the rows and one for the columns. Also, for each cell, store an LWW map of format key-value pairs; mutate the map when the user formats that individual cell. To compute the current bold format for a cell, consider:
- The current (largest timestamp) bold mark for the cell’s row.
- The current bold mark for its column.
- The value at key “bold” in the cell’s own LWW map.
Then render the mark/value with the largest timestamp out of these three.
This idea lets you format rows, columns, and cells separately. Sequential formatting ops interact in the expected way: for example, if a user bolds a row and then unbolds a column, the intersecting cell is not bold, since the column op has a larger timestamp.
Global Modifiers
Often you want an operation to do something “for each” element of a collection, including elements added concurrently.
Example: An inline formatting mark affects each character in its range, including characters inserted concurrently (see above).
Example: Suppose a recipe editor has a “Halve the recipe” button, which halves every ingredient’s amount. This should have the semantics: for each ingredient amount, including amounts set concurrently, halve it. If you don’t halve concurrent set ops, the recipe can get out of proportion:
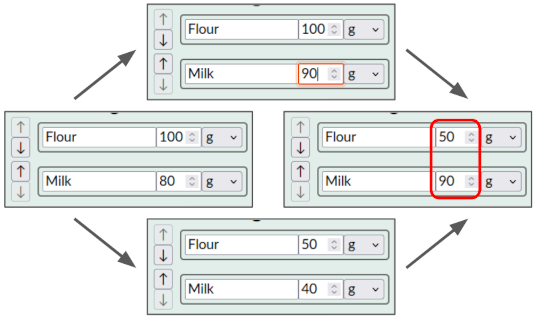
I’ve talked about these for-each operations before and co-authored a paper formalizing them (Weidner et al. 2023). However, the descriptions so far query the causal order (below), making them difficult to implement.
Instead, I currently recommend implementing these examples using global modifiers. By “global modifier”, I mean a piece of state that affects all elements of a collection/range: causally prior, concurrent, and (causally) future.
The inline formatting marks above have this form: a mark affects each character in its range, regardless of when it was inserted. If a user decides that a future character should not be affected, that user can override the formatting mark with a new one.
To implement the “Halve the recipe” example:
- Store a global scale alongside the recipe. This is a number controlled by LWW, which you can think of as the number of servings.
- Store each ingredient’s amount as a scale-independent number. You can think of this as the amount per serving.
- The app displays the product
ingrAmount.value * globalScale.valuefor each ingredient’s amount. - To halve the recipe, merely set the global scale to half of its current value:
globalScale.set(0.5 * globalScale.value). This halves all displayed amounts, including amounts set concurrently and concurrently-added ingredients. - When the user sets an amount, locally compute the corresponding scale-independent amount, then set that. E.g. if they change flour from 50 g to 55 g but the global scale is 0.5, instead call
ingrAmount.set(110).
In the recipe editor, you could even make the global scale non-collaborative: each user chooses how many servings to display on their own device. But all collaborative edits affect the same single-serving recipe internally.
Refs: Weidner, Miller, and Meiklejohn 2020; Weidner et al. 2023
Forests and Trees
Many apps include a tree or forest structure. (A forest is a collection of disconnected trees.) Typical operations are creating a new node, deleting a node, and moving a node (changing its parent).
Examples: A file system is a tree whose leaves are files and inner nodes are folders. A Figma document is a tree of rendered objects.
The CRDT way to represent a tree or forest is: Each node has a parent node, set via LWW. The parent can either be another node, a special “root” node (in a tree), or “none” (in a forest). You compute the tree/forest as a view of these child->parent relationships (edges) in the obvious way.
When a user deletes a node - implicitly deleting its whole subtree - don’t actually loop over the subtree deleting nodes. That would have weird results if another user concurrently moved some nodes into or out of the subtree. Instead, only delete the top node (or archive it - e.g., set its parent to a special “trash” node). It’s a good idea to let users view the deleted subtree and move nodes out of it.
Everything I’ve said so far is just an application of basic techniques. Cycles are what make forests and trees advanced: it’s possible that one user sets B.parent = A, while concurrently, another user sets A.parent = B. Then it’s unclear what the computed view should be.
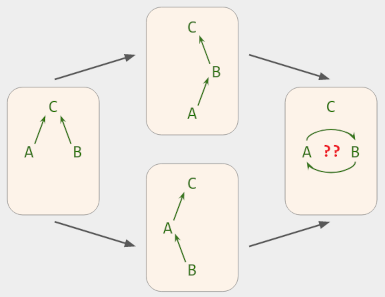
Figure 6. Concurrent tree-move operations - each valid on their own - may create a cycle. When this happens, what state should the app display, given that cycles are not allowed in a forest/tree?
Some ideas for how to handle cycles:
- Error. Some desktop file sync apps do this in practice (Kleppmann et al. (2022) give an example).
- Render the cycle nodes (and their descendants) in a special “time-out” zone. They will stay there until some user manually fixes the cycle.
- Use a server to process move ops. When the server receives an op, if it would create a cycle in the server’s own state, the server rejects it and tells users to do likewise. This is what Figma does. Users can still process move ops optimistically, but they are tentative until confirmed by the server. (Optimistic updates can cause temporary cycles for users; in that case, Figma uses strategy (2): it hides the cycle nodes.)
- Similar, but use a topological sort (below) instead of a server’s receipt order. When processing ops in the sort order, if an op would create a cycle, skip it (Kleppmann et al. 2022).
- For forests: Within each cycle, let
B.parent = Abe the edge whosesetoperation has the largest LWW timestamp. At render time, “hide” that edge, instead renderingB.parent = "none", but don’t change the actual CRDT state. This hides one of the concurrent edges that created the cycle.- To prevent future surprises, users’ apps should follow the rule: before performing any operation that would create or destroy a cycle involving a hidden edge, first “affirm” that hidden edge, by performing an op that sets
B.parent = "none".
- To prevent future surprises, users’ apps should follow the rule: before performing any operation that would create or destroy a cycle involving a hidden edge, first “affirm” that hidden edge, by performing an op that sets
- For trees: Similar, except instead of rendering
B.parent = "none", render the previous parent forB- as if the bad operation never happened. More generally, you might have to backtrack several operations. Both Hall et al. (2018) and Nair et al. (2022) describe strategies along these lines.
Refs: Graphs in Shapiro et al. 2011a; Martin, Ahmed-Nacer, and Urso 2011; Hall et al. (2018); Nair et al. 2022; Kleppmann et al. 2022; Wallace 2022
Undo/Redo
In most apps, users should be able to undo and redo their own operations in a stack, using Ctrl+Z / Ctrl+Shift+Z. You might also allow selective undo (undo operations anywhere in the history) or group undo (users can undo each others’ operations) - e.g., for reverting changes.
A simple way to undo an operation is: perform a new operation whose effect locally undoes the target operation. For example, to undo typing a character, perform a new operation that deletes that character.
However, this “local undo” has sub-optimal semantics. For example, suppose one user posts an image, undoes it, then redoes it; concurrently to the undo/redo, another user comments on the image. If you implement the redo as “make a new post with the same contents”, then the comment will be lost: it attaches to the original post, not the re-done one.
Exact undo instead uses the following semantics:
- In addition to normal app operations, there are operations
undo(opID)andredo(opID), whereopIDidentifies a normal operation. - For each
opID, consider the history ofundo(opID)andredo(opID)operations. Apply some boolean-value CRDT to that operation history to decide whetheropIDis currently (re)done or undone. - The current state is the result of applying your app’s semantics to the (re)done operations only.
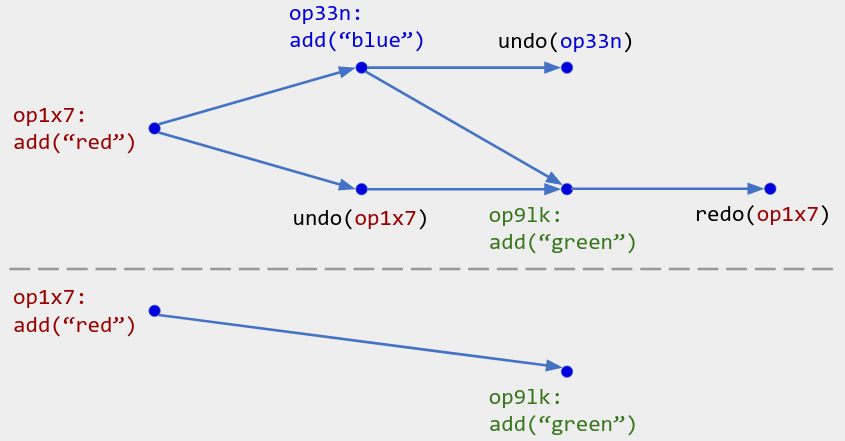
Figure 7. Top: Operation history for an add-wins set with exact undo. Currently, op1x7 is redone, op33n is undone, and op91k is done.
Bottom: We filter the (re)done operations only and pass the filtered operation history to the add-wins set's semantics, yielding state { "red", "green" }.
For the boolean-value CRDT, you can use LWW, or a multi-value register’s displayed value (e.g., redo-wins). Or, you can use the maximum causal length: the first undo operation is undo(opID, 1); redoing it is redo(opID, 2); undoing it again is undo(opID, 3), etc.; and the winner is the op with the largest number. (Equivalently, the head of the longest chain of causally-ordered operations - hence the name.)
Maximum causal length makes sense as a general boolean-value CRDT, but I’ve only seen it used for undo/redo.
Step 3 is more difficult that it sounds. Your app might assume causal-order delivery, then give weird results when undone operations violate it. (E.g., our multi-value register algorithm above will not match the intended semantics after undos.) Also, most algorithms do not support removing past operations from the history. But see Brattli and Yu (2021) for a multi-value register that is compatible with exact undo.
Refs: Weiss, Uros, and Molli 2010; Yu, Elvinger, and Ignat 2019
Other Techniques
This section mentions other techniques that I personally find less useful. Some are designed for distributed data stores instead of collaborative apps; some give reasonable semantics but are hard to implement efficiently; and some are plausibly useful but I have not yet found a good example app.
Remove-Wins Set
The remove-wins set is like the add-wins set, except if there are concurrent operations add(x) and remove(x), then the remove wins: x is not in the set. You can implement this similarly to the add-wins set, using a disable-wins flag instead of enable-wins flag. (Take care that the set starts empty, instead of containing every possible value.) Or, you can implement the remove-wins set using:
- an append-only log of all values that have ever been added, and
- an add-wins set indicating which of those values are currently removed.
In general, any implementation must store all values that have ever been added; this is a practical reason to prefer the add-wins set instead. I also do not know of an example app where I prefer the remove-wins set’s semantics. The exception is apps that already store all values elsewhere, such as an archiving collection: I think a remove-wins set of present values would give reasonable semantics. That is equivalent to using an add-wins set of archived values, or to using a disable-wins flag for each value’s isPresent field.
Refs: Bieniusa et al. 2012; Baquero, Almeida, and Shoker 2017; Baquero et al. 2017
PN-Set
The PN-Set (Positive-Negative Set) is another alternative to the add-wins set. Its semantics are: for each value x, count the number of add(x) operations in the operation history, minus the number of remove(x) operations; if it’s positive, x is in the set.
This semantics give strange results in the face of concurrent operations, as described by Shapiro et al. (2011a). For example, if two users call add(x) concurrently, then to remove x from the set, you must call remove(x) twice. If two users do that concurrently, it will interact strangely with further add(x) operations, etc.
Like the maximum causal length semantics, the PN-Set was originally proposed for undo/redo.
Refs: Weiss, Urso, and Molli 2010; Shapiro et al. (2011a)
Observed-Reset Operations
An observed-reset operation cancels out all causally prior operations. That is, when looking at the operation history, you ignore all operations that are causally prior to any reset operation, then compute the state from the remaining operations.
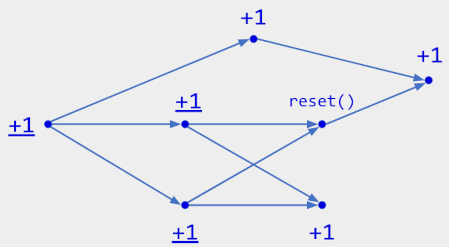
Figure 8. Operation history for a counter with +1 and observed-reset operations. The reset operation cancels out the underlined +1 operations, so the current state is 3.
Observed-reset operations are a tempting way to add a delete(key) operation to a map-like object: make delete(key) be an observed-reset operation on the value CRDT at key. Thus delete(key) restores a value CRDT to its original, unused state, which you can treat as the “key-not-present” state. However, then if one user calls delete(key) while another user operates on the value CRDT concurrently, you’ll end with an awkward partial state:
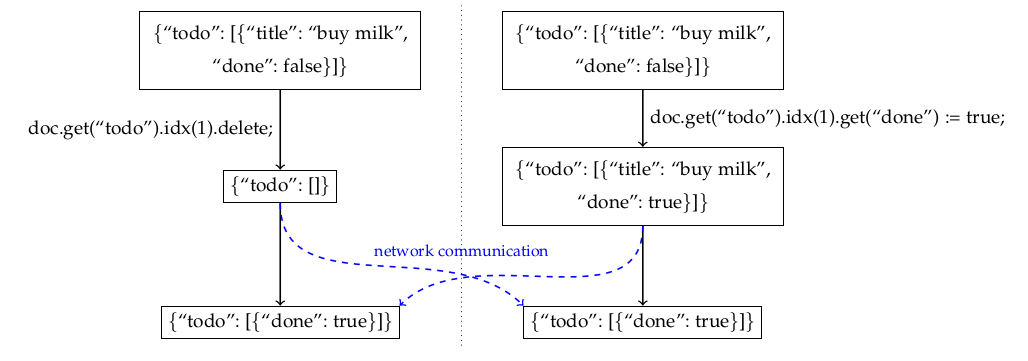
Image credit: Figure 6 by Kleppmann and Beresford. That paper describes a theoretical JSON CRDT, but Firebase RTDB has the same behavior.
I instead prefer to omit delete(key) from the map-like object entirely. If you need deletions, instead use a CRDT-valued map or similar. Those ultimately treat delete(key) as a permanent deletion (from the unique-set of CRDTs) or as an archive operation.
Refs: Deletes in Riak Map
Querying the Causal Order
Most of our techniques so far don’t use the causal order on operations (arrows in the operation history). However, the multi-value register does: it queries the set of causally-maximal operations, displaying their values. Observed-reset operations also query the causal order, and the add-wins set/remove-wins set reference it indirectly.
One can imagine CRDTs that query the causal order in many more ways. However, I find these too complicated for practical use:
- It is expensive to track the causal order on all pairs of operations.
- Semantics that ask “is there an operation concurrent to this one?” generally need to store operations forever, in case a concurrent operation appears later.
- It is easy to create semantic rules that don’t behave well in all scenarios.
(The multi-value register and add-wins set occupy a special case that avoids (1) and (2).)
As an example of (3), it is tempting to define an add-wins set by: an add(x) operation overrules any concurrent remove(x) operation, so that the add wins. But then in Figure 9’s operation history, both remove(x) operations get overruled by concurrent add(x) operations. That makes x present in the set when it shouldn’t be.
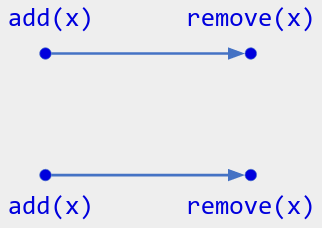
Figure 9. Operation history for an add-wins set. One user calls add(x) and then remove(x); concurrently, another user does likewise. The correct current state is the empty set: the causally-maximal operations on x are both remove(x).
As another example, you might try to define an add-wins set by: if there are concurrent add(x) and remove(x) operations, apply the remove(x) “first”, so that add(x) wins; otherwise apply operations in causal order. But then in the above operation history, the intended order of operations contains a cycle:
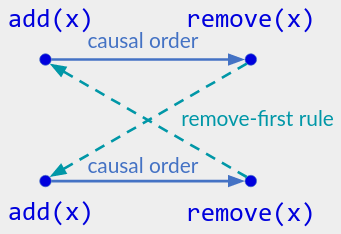
I always try out this operation history when a paper claims to reproduce/understand the add-wins set in a new way.
Topological Sort
A topological sort is a general way to “derive” CRDT semantics from an ordinary data structure. Given an operation history made out of ordinary data structure operations, the current state is defined by:
- Sort the operations into some consistent linear order that is compatible with the causal order (
o < pimpliesoappears beforep). E.g., sort them by Lamport timestamp. - Apply those operations to the starting state in order, returning the final state. If an operation would be invalid (e.g. it would create a cycle in a tree), skip it.
The problem with these semantics is that you don’t know what result you will get - it depends on the sort order, which is fairly arbitrary.
However, topological sort can be useful as a fallback in complex cases, like tree cycles or group-chat permissions. You can think of it like asking a central server for help: the sort order stands in for “the order in which ops reached the server”. (If you do have a server, you can use that instead.)
Ref: Kleppmann et al 2018
Capstones
Let’s finish by designing novel semantics for two practical but complex collaborative apps.
Recipe Editor
I’ve mentioned a collaborative recipe editor in several examples. It’s implemented as a Collabs demo: live demo, talk slides, talk video, source code.
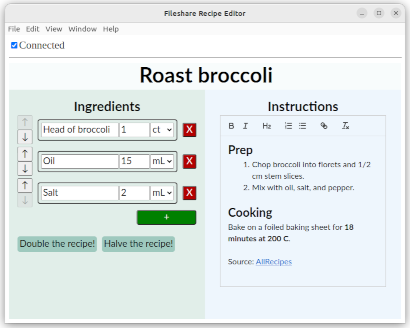
The app’s semantics can be described compositionally using nested objects. Here is a schematic:
{
ingredients: UniqueSetOfCRDTs<{
text: TextCRDT,
amount: LWWRegister<number>, // Scale-independent amount
units: LWWRegister<Unit>,
position: LWWRegister<Position>, // List CRDT position, for list-with-move
isPresent: EnableWinsFlag // For update-wins semantics
}>,
globalScale: LWWRegister<number>, // For scale ops
description: {
text: TextCRDT,
formatting: InlineFormattingCRDT
}
}
(Links by class name: UniqueSetOfCRDTs, TextCRDT, LWWRegister, EnableWinsFlag, InlineFormattingCRDT.)
Most GUI operations translate directly to operations on this state, but there are some edge cases.
- The ingredient list is a list-with-move: move operations (the arrow buttons) set
position. - Delete operations (the red X’s) use update-wins semantics: delete sets
isPresentto false, while each operation on an ingredient (e.g., setting its amount) additionally setsisPresentto true. - Ingredient amounts, and the “Double the recipe!” / “Halve the recipe!” buttons, treat the scale as a global modifier.
Block-Based Rich Text
We described inline rich-text formatting above, like bold and italics. Real rich-text editors also support block formatting: headers, lists, blockquotes, etc. Fancy apps like Notion even let you rearrange the order of blocks using drag-and-drop:

Let’s see if we can design a CRDT semantics that has all of these features: inline formatting, block formatting, and movable blocks. Like the list-with-move, moving a block should not affect concurrent edits within that block. We’d also like nice behavior in tricky cases - e.g., one user moves a block while a concurrent user splits it into two blocks.
This section is experimental; I’ll update it in the future if I learn of improvements (suggestions are welcome).
Refs: Ignat, André, and Oster 2017 (similar Operational Transformation algorithm); Quill line formatting; unpublished notes by Martin Kleppmann (2022); Notion’s data model
CRDT State
The CRDT state is an object with several components:
text: A text CRDT. It stores the plain text characters plus two kinds of invisible characters: block markers and hooks. Each block marker indicates the start of a block, while hooks are used to place blocks that have been split or merged.format: An inline formatting CRDT on top oftext. It controls the inline formatting of the text characters (bold, italic, links, etc.). It has no effect on invisible characters.blockList: A separate list CRDT that we will use to order blocks. It does not actually have content; it just serves as a source of list CRDT positions.- For each block marker (keyed by its list CRDT position), a block CRDT object with the following components:
blockType: An LWW register whose value is the block’s type. This can be “heading 2”, “blockquote”, “unordered list item”, “ordered list item”, etc.indent: An LWW register whose value is the block’s indent level (a nonnegative integer).placement: An LWW register that we will explain later. Its value is one of:{ case: "pos", target: <position in blockList> }{ case: "origin", target: <a hook's list CRDT position> }{ case: "parent", target: <a hook's list CRDT position>, prevPlacement: <a "pos" or "origin" placement value> }
Rendering the App State
Let’s ignore blockCRDT.placement for now. Then rendering the rich-text state resulting from the CRDT state is straightforward:
- Each block marker defines a block.
- The block’s contents are the text immediately following that block marker in
text, ending at the next block marker. - The block is displayed according to its
blockTypeandindent.- For ordered list items, the leading number (e.g. “3.”) is computed at render time according to how many preceding blocks are ordered list items. Unlike in HTML, the CRDT state does not store an explicit “list start” or “list end”.
- The text inside a block is inline-formatted according to
format. Note that formatting marks might cross block boundaries; this is fine.

Figure 10. Sample state and rendered text, omitting blockList, hooks, and blockCRDT.placement.
Now we need to explain blockCRDT.placement. It tells you how to order a block relative to other blocks, and whether it is merged into another block.
- If
caseis"pos": This block stands on its own. Its order relative to other"pos"blocks is given bytarget’s position inblockList. - If
caseis"origin": This block again stands on its own, but it follows another block (its origin) instead of having its own position. Specifically, let block A be the block containingtarget(i.e., the last block marker prior totargetintext). Render this block immediately after block A. - If
caseis"parent": This block has been merged into another block (its parent). Specifically, let block A be the block containingtarget. Render our text as part of block A, immediately after block A’s own text. (OurblockTypeandindentare ignored.)
![Top: "blockList: [p32x, p789]". Middle: "text: _Hel^lo_Ok^_ay" with underscores labeled "Block marker n7b3", "Block marker ttx7", "Block marker x1bc", and carets labeled "Hook @ pbj8", "Hook @ p6v6". Bottom left: 'n7b3.placement: { case: “pos”, target: p32x }', 'ttx7.placement: { case: “origin”, target: pbj8 }', 'x1bc.placement: { case: “parent”, target: p6v6 }'. Bottom right: two rendered blocks, "1. Hello" and "(blockquote) Okay".](/assets/img/crdt-survey/block_header_placement.png)
Figure 11. Repeat of Figure 10 showing blockList, hooks, and blockCRDT.placement. Observe that "Okay" is the merger of two blocks, "Ok" and "ay".
You might notice some dangerous edge cases here! We’ll address those shortly.
Move, Split, and Merge
Now we can implement the three interesting block-level operations:
- Move. To move block B so that it immediately follows block A, first create a new position in
blockListthat is immediately after A’s position (or its origin’s (origin’s…) position). Then set block B’splacementto{ case: "pos", target: <new blockList position> }.- If there are any blocks with origin B that you don’t want to move along with B, perform additional move ops to keep them where they currently appear.
- If there are any blocks with origin A, perform additional move ops to move them after B, so that they aren’t rendered between A and B.
- Edge case: to move block B to the start, create the position at the beginning of
blockList.
- Split. To split a block in two, insert a new hook and block marker at the splitting position (in that order). Set the new block’s
placementto{ case: "origin", target: <new hook's position> }, and set itsblockTypeandindentas you like.- Why do we point to a hook instead of the previous block’s block header? Basically, we want to follow the text just prior to the split, which might someday end up in a different block. (Consider the case where the previous block splits again, then one half moves without the other.)
- Merge. To merge block B into the previous block, first find the previous block A in the current rendered state. (This might not be the previous block marker in
text.) Insert a new hook at the end of A’s rendered text, then set block B’splacementto{ case: "parent", target: <new hook's position>, prevPlacement: <block B's previous placement value> }.- The “end of A’s rendered text” might be in a block that was merged into A.
Edge Cases
It remains to address some dangerous edge cases during rendering.
First, it is possible for two blocks B and C to have the same origin block A. So according to the above rules, they should both be rendered immediately after block A, which is impossible. Instead, render them one after the other, in the same order that their hooks appear in the rendered text. (This might differ from the hooks’ order in text.)
More generally, the relationships “block B has origin A” form a forest. (I believe there will never be a cycle, so we don’t need our advanced technique above.) For each tree in the forest, render that tree’s blocks consecutively, in depth-first pre-order traversal order.
![Top: "blockList: [p32x, p789]. Bottom: "Forest of origins" with nodes A-E and edges B to A, C to B, D to A. Nodes A and E have lines to p32x and p789, respectively.](/assets/img/crdt-survey/origin_forest.png)
Figure 12. A forest of origin relationships. This renders as block order A, B, C, D, E. Note that the tree roots A, E are ordered by their positions in blockList.
Second, it is likewise possible for two blocks B and C to have the same parent block A. In that case, render both blocks’ text as part of block A, again in order by their hooks.
More generally, we would like the relationships “block B has parent A” to form a forest. However, this time cycles are possible!
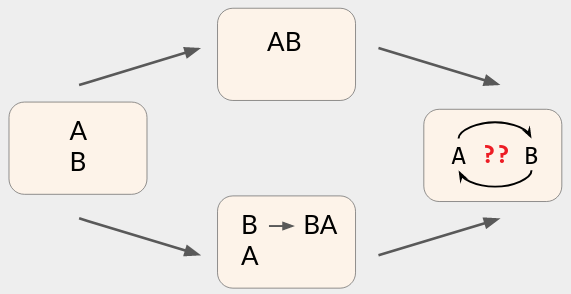
Figure 13. One user merges block B into A. Concurrently, another user moves B above A, then merges A into B. Now their parent relationships form a cycle.
To solve this, use any of the ideas from forests and trees to avoid/hide cycles. I recommend a variant of idea 5: within each cycle, “hide” the edge with largest LWW timestamp, instead rendering its prevPlacement. (The prevPlacement always has case "pos" or "origin", so this won’t create any new cycles. Also, I believe you can ignore idea 5’s sentence about “affirming” hidden edges.)
Third, to make sure there is always at least one block, the app’s initial state should be: blockList contains a single position; text contains a single block marker with placement = { case: "pos", target: <the blockList position> }.
Why does moving a block set its
placement.targetto a position withinblockList, instead of a hook like Split/Merge? This lets us avoid another cycle case: if block B is moved after block A, while concurrently, block A is moved after block B, thenblockListgives them a definite order without any fancy cycle-breaking rules.
Validation
I can’t promise that these semantics will give a reasonable result in every situation. But following the advice in Composition Techniques, we can check all interesting pairs of concurrent operations, then trust that the general case at least satisfies strong convergence (by composition).
The following figure shows what I believe will happen in various concurrent situations. In each case, it matches my preferred behavior. Lines indicate blocks, while A/B/C indicate chunks of text.
Conclusion
A CRDT-based app’s semantics describe what the state of the app should be, given a history of collaborative operations. Choosing semantics is ultimately a per-app problem, but the CRDT literature provides many ideas and examples.
This blog post was long because there are indeed many techniques. However, we saw that they are mostly just a few basic ideas (UIDs, list CRDT positions, LWW, multi-value register) plus composed examples.
It remains to describe algorithms implementing these semantics. Although we gave some basic CRDT algorithms in-line, there are additional nuances and optimizations. Those will be the subject of the next post, Part 3: Algorithmic Techniques.
This blog post is Part 2 of a series.
Home • Matthew Weidner • Common Curriculum / CMU PhD student • mweidner037 [at] gmail.com • @MatthewWeidner3 • @mweidner.bsky.social • LinkedIn • GitHub